Мониторинг нагрузки серверов — задача, которая может быть решена с помощью таких инструментов, как Zabbix, Grafana или Icinga, но все они требуют наличия дополнительных ресурсов и сложной установки. К тому же для мониторинга единственного сервера их возможности могут быть избыточными. Поэтому для оценки нагрузки одного сервера можно воспользоваться таким инструментом, как atop.
Мы рекомендуем atop: он легко устанавливается, не требует тонких настроек и практически не использует ресурсы сервера. Фактически эта служба делает снимки по нагрузке системы в моменте, через определенные интервалы времени. По этим снимкам можно потом отследить, какие службы избыточно потребляли ресурсы системы при возникновении проблемы. Единственный минус — работать с ним можно только через ssh. Если для вас это не проблема, расскажем, как поставить atop и пользоваться им.
Установка и настройка
Debian/Ubuntu
установка
apt install atop
Проверить статус службы можно с помощью команды:
systemctl status atop
В выводе команды также будет доступна информация о добавлении службы в автозагрузку:

Если в выводе указано enabled – значит, всё в порядке, и после перезагрузки эта служба будет автоматически загружена системой. Если видите статус disabled, это означает, что необходимо добавить службу в автозагрузку командой:
systemctl enable atop
Centos
установка
yum install atop
Возможно, система не найдет этого пакета и выдаст следующую ошибку:
No package atop available.
Error: Nothing to do
В этом случае сначала необходимо включить репозиторий epel:
yum install epel-release
И уже затем повторно запустить установку atop. Далее добавляем службу в автозапуск:
systemctl enable atop
И запускаем:
systemctl start atop
Конфигурационный файл
Debian/Ubuntu: находится в /etc/default/atop.
CentOS: находится в /etc/sysconfig/atop.
Пример конфигурационного файла:
# Ubuntu 22.04
# /etc/default/atop
# see man atoprc for more possibilities to configure atop execution
LOGOPTS="-R"
LOGINTERVAL=600
LOGGENERATIONS=28
LOGPATH=/var/log/atop
#CentOS 7
LOGOPTS=""
LOGINTERVAL=600
LOGGENERATIONS=28
LOGPATH=/var/log/atop
Если конфигурация вас устраивает, можете оставить все как есть. Но если вам необходимо изменить период хранения логов или любые другие параметры, то после изменения конфигурации следует перезапустить службу atop для её применения командой:
systemctl restart atop
Можно также убедиться в корректности файла конфигурации, т.е. корректности значений переменных в конфигурации, если прочитать конфигурацию юнита через systemd. Например, для Ubuntu 22.04 можно воспользоваться следующей командой для чтения конфигурации:
systemctl cat atop
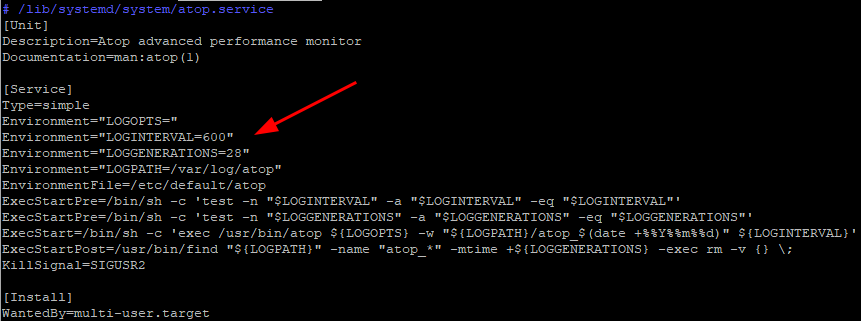
На скрине выше указаны названия переменных по умолчанию и, если они были не определены и/или неправильно определены в файле конфигурации, то будут определяться этими значениями.
На этом можно считать, что настройка atop завершена.
Как пользоваться atop?
Отчеты по системе можно просматривать, используя atop или atopsar.
Команда atopsar — это встроенный анализатор логов atop, который позволит быстро найти проблему и смотреть лог в нужное вам время. При этом atopsar использует цвета и (по запросу) маркеры, чтобы подчеркнуть, что использование ресурса является критическим (красный) или почти критическим (голубой).
Общая структура команды:
atopsar [-flags] [-r file|date|y...] [-R cnt] [-b hh:mm] [-e hh:mm]
Также при указании названия файла, из которого будет формироваться отчет, можно создавать короткую запись, состоящую только из y, например, 'yyy' – в данном случае будет читаться файл atop 3-дневной давности. Если сегодня 10.02.24, то будет использован файл от 07.02.24. Можно просто указать 'y' и будет использован файл за прошлый день.
Например, такая команда выведет отчет о средней нагрузке за позавчера :
atopsar -r yy -R12 -p
Основные ключи:
-b — с какого времени надо вывести лог,
-e — до какого времени надо вывести лог,
-R — позволяет объединить несколько снимков системы в один.
Например, если у вас в системе установлено значение интервала записи на 300 секунд, то флаг '-R 12' позволит увидеть общую информацию за каждый час. Бывает полезно для локализации проблемы, если вам неизвестно точное время проблемы.
Например, команда:
atopsar -r yyyy -R24 -d -b 10:00 -e 16:00
Она выведет информацию по нагрузке на каждый диск отдельно из лога 4 дня назад с 10:00 до 16:00 с шагом в 2 часа.
При этом на нашем тестовом сервере значение LOGINTERVAL=300, поэтому значение установили '-R 24' для вывода информации за каждые 2 часа. В вашем случае оно может отличаться.

Общая нагрузка:
-d — нагрузка на каждый диск отдельно
-m — нагрузка на оперативную память и swap
-с — нагрузка на процессор, отдельно по каждому ядру
-p — информация по средней нагрузке (LA) и аппаратным прерываниям
-w — нагрузка на ipv4
-W — ошибки на ipv4
-i — нагрузка на интерфейс
-I — ошибки на сетевых интерфейсах
Допускается комбинирование ключей в одной команде, например, если нам необходимо увидеть нагрузку на процессор и использование памяти в отчётах, то можно указать ключи вместе:
atopsar -mс -r /var/log/atop/atop_20240205
В этом случае atopsar сформирует 2 отчета – по нагрузке на процессор и оперативную память.
Поиск отдельных процессов*:
-O — top-3 процессов CPU
-G — top-3 процессов RAM
-D — top-3 процессов диск
-N — top-3 процессов сеть
*данные флаги не допускают флаг -R.
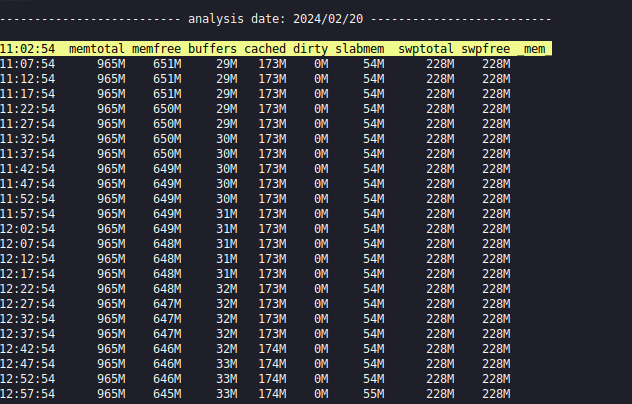
Пример. Нагрузка на RAM с 11:00 до 21:00 20 февраля:atopsar -r /var/log/atop/atop_20240220 -b 11:00 -e 21:00 -m
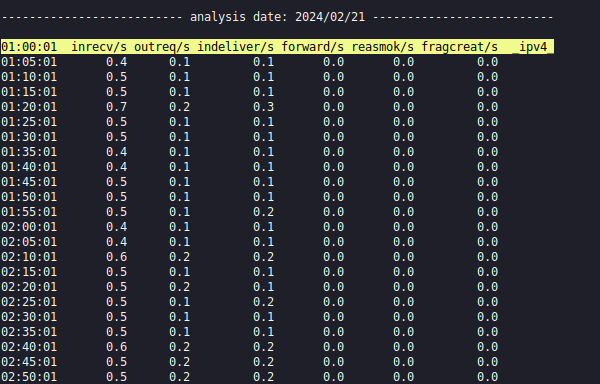
Нагрузка по сетевым интерфейсам:atopsar -r /var/log/atop/atop_20240221 -b 1:00 -e 6:00 -w
Нагрузка на диски:atopsar -r /var/log/atop/atop_20240221 -b 9:00 -e 15:00
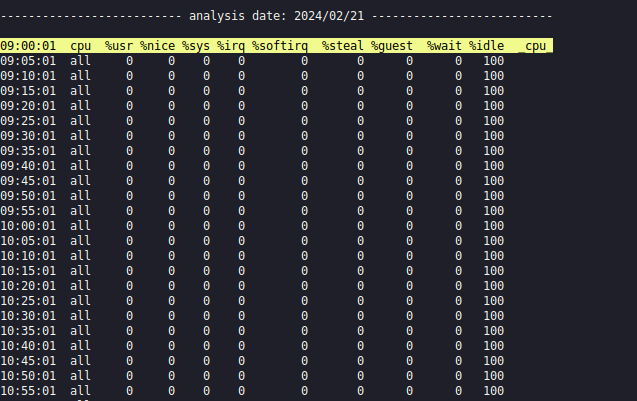
Пример следующей команды поможет вам понять, какие процессы занимают больше всего оперативной памяти на сервере в процентах от общей памяти и в какой момент времени:
atopsar -r /var/log/atop/atop_20240221 -b 9:00 -e 17:00 -G
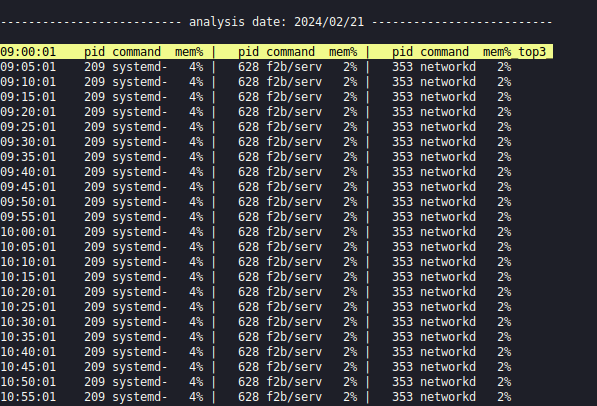
Если вам этого недостаточно, можно посмотреть полный снимок нагрузки на сервер командой:atop -r путь до лога, можно сразу указать временные рамки.
Например: atop -r /var/log/atop/atop_20240211 -b 09:00 -e 20:00
Откроется тот же atop, в котором видна вся нагрузка на сервере, где можно выставлять сортировку по процессам, но только на нужное время. Чтобы открыть следующий снимок нагрузки, нажмите t, предыдущий снимок — T. Время снимка указано в первой строке посередине экрана.
Также необходимо обратить внимание на использование цветов в выводимой информации. По умолчанию параметры в верхней части экрана atop меняют цвета в зависимости от процента использования ресурса системой. Когда использование ресурсов становится критичным для системы, atop меняет цвет сначала на синий, затем — на красный. Эти проценты немного различаются в зависимости от типа ресурса:
- для процессора – 90 %;
- для использования сети – 90 %;
- для оперативной памяти – 90 %;
- для дисковой системы – 70 %;
- для swap – 80 %;
Эти параметры могут быть изменены в файле ~/.atoprc для более тонкой настройки, если он создан. По умолчанию такого файла нет.
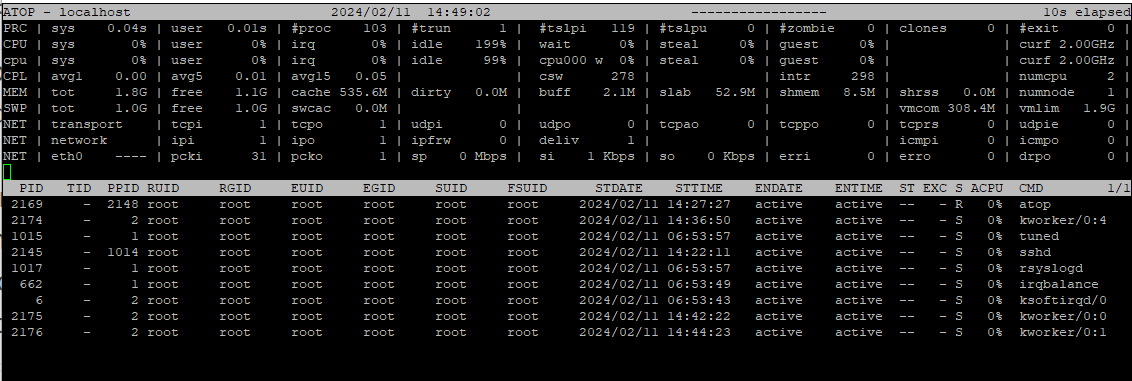
На скрине выше в верхней части представлены основные параметры системы:
- Строка PRC – отображает общие данные на уровне процессов и потоков:
- sys, user – общее время процессора, затраченное в системном режиме и в пользовательском режиме соответственно;
- #proc – общее количество процессов, активных в системе на текущий момент;
- #trun – общее количество потоков, активных в данный момент;
- #tslpi – общее количество потоков, которые сейчас находятся в спящем режиме и могут быть прерваны;
- #tslpu – общее количество потоков, которые в текущее время находятся в спящем режиме и не могут быть прерваны;
- #zombie – количество процессов-зомби;
- clones – количество системных вызовов клонов для процессов;
- #exit – количество процессов, завершившихся за прошедшее время.
- Строка CPU – выводит общие данные о нагрузке на центральный процессор. Верхняя строка показывает общую занятость для всего процессора. В случае многоядерной системы для каждого отдельного ядра отображается дополнительные строки с «cpu» в нижнем регистре, отсортированные по активности. Для каждого ядра и всего процессора содержатся следующие показатели:
- sys, user – общее время процессора, затраченное в системном режиме и в пользовательском режиме соответственно;
- irq – процент времени процессора, затраченного на обработку прерываний;
- idle – процент неиспользованного времени процессора, когда ни один из процессов не ожидает дискового ввода-вывода;
- wait – процент неиспользованного времени процессора, пока по крайней мере один процесс ждал дисковый ввод-вывод;
- Строка CPL – показывает LA (Load Average) за 1, 5 и 15 минут, а также количество доступных ядер процессора.
- Строка MEM – показывает общую информацию об оперативной памяти:
- tot – общий объем доступной оперативной памяти;
- free – общий объем свободной памяти;
- cache – текущий объем кэш-памяти;
- dirty – объем памяти в страничном кэше, который необходимо сбросить на диск;
- buff – объем памяти, используемый для метаданных файловой системы;
- Строка Swap – показывает общую информацию о swap.
- Строка DSK — показывает использование диска:
- busy – процент времени, в течение которого система занята обработкой запросов;
- read – выданные запросы на чтение;
- write – выданные запросы на запись;
- KiB/r и KiB/w – скорость чтения и записи данных (в КB) на каждый запрос;
- MBr/s и MBw/s – временные показатели для чтения и записи на диск в мегабайтах.
- avio – среднее количество миллисекунд, затраченных на обработку запросов.
- Строки NET – показывают общую статистику использованию сети на транспортном и сетевом уровне, а также отдельно по каждому активному сетевому интерфейсу.
В данном окне (см. скрин выше) можно применять следующие горячие клавиши для изменения нижней части окна:
- для изменения отображения таблицы процессов — отвечает за просмотр:
'm' - памяти, используемой процессами;
'd' - использования диска процессами;
'n' - использования сети;
'v' - детальной информации по процессам (ppid, user/group, date/time, status, exitcode)
'c' - полной команды для каждого процесса.
- для сортировки по использованию:
'C' - процессора;
'M' - оперативной памяти;
'D' - оперативной дисковой системы;
'N' - оперативной дисковой сети;
'A' - самые активные пользователи ресурсов (auto mode).
- для суммирования:
'u' - по пользователям системы;
'p' - по процессам.
- для поиска* — фокус на определённом:
'U' - пользователе системы;
'P' - процессе по названию;
'I' - процессе по PID;
'/' - выражении командной строки или её части.
*После ввода горячей клавиши необходимо ввести слово или регулярное выражение.
Дополнительная информация в статье «Нагрузка на сервер: определение причин».
