Виртуальная машина не всегда работает с ожидаемой скоростью. Сайт внезапно начинает тормозить, скрипты выполняются долго. В этой статье мы покажем каким образом можно анализировать производительность виртуальной машины и находить причины замедлений в работе.
В центре нашего внимания будут нагрузки, связанные с использованием центрального процессора и жесткого диска.
- Команда top
- Средняя нагрузка на систему (load average)
- Параметр Cpu
- Нагрузка на процессор (параметры sy, us, ni)
- Определение оверселлинга (параметр st)
- Нагрузка ввода-вывода (параметр wa)
- Нагрузка ввода-вывода: копаем глубже (atop)
- Заключение
Постараемся ответить на вопрос: что делать в случае проблем на сервере, какие инструменты использовать и на что обращать внимание для диагностирования проблем производительности в операционной системе Linux.
Команда top
Главным инструментом в этом деле станет команда top. Результат её выполнения выглядит так:
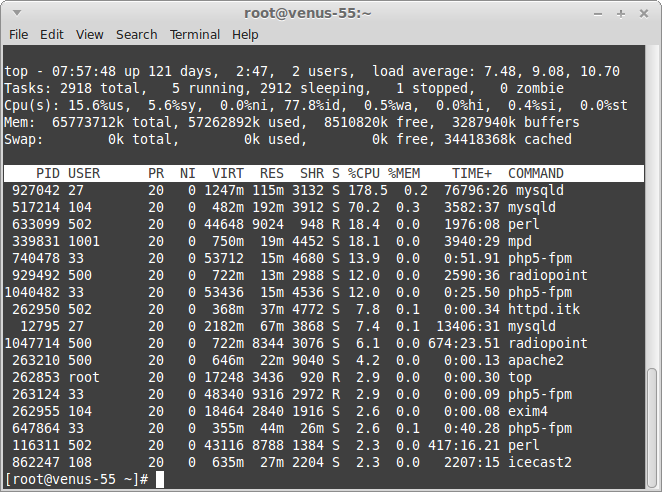
Программа top выдает динамическое представление о работающей системе в реальном времени. Верхнюю часть вывода занимает краткая обобщённая информация, нижнюю часть — список запущенных процессов.
Рассмотрим основные показатели, которые могут нас заинтересовать.
Средняя нагрузка на систему (load average)

Load Average — среднее значение загруженности системы за период времени (в дальнейшем LA). Три значения показывают усреднённую нагрузку за последние 1, 5 и 15 минут. LA является одним из самых спорных показателей. Можно найти множество противоречивых статей, какое значение считать нормальным. Обычно принимается, что значение 0 это простой ядра, а значение 1 это полная нагрузка ядра. Оценить показатель средней нагрузки можно только зная количество ядер в системе. Узнать сколько ядер доступно можно командой:
dmidecode -t processor | grep "Core Enabled:" Core Enabled: 6 Core Enabled: 6
Видим, что на данной системе находится 12 физических ядер (6+6). Соответственно, нормальный показатель LA должен быть менее 12. Однако, на процессорах Intel используется технология Hyper-Threading, которая делит одно физическое ядро на два логических.
dmidecode -t processor | grep "Thread Count:" Thread Count: 12 Thread Count: 12
Соответственно, в данном случае в системе может быть одновременно 24 виртуальных процессора (потока).
Технология Turbo Boost позволяет процессору «разгоняться» и работать на частоте выше заявленной (т.е. выше 100%, выше единицы). Какой показатель LA считать нормальным в данном случае является предметом споров.
Были попытки вычислить нормальное значение LA эмпирическим путем. Но мы считаем это бессмысленным занятием. Дело в том, что в LA попадают также процессы, стоящие в очереди чтения/записи и не имеющие отношение к процессору, а также процессы с приоритетом, измененным с помощью команды nice. В случае если команда запущенна с низким приоритетом, она будет находится в очереди, но не будет оказывать влияния на реальную производительность.
Высокий LA может сигнализировать о каких-либо проблемах. С другой стороны, высокое значение не обязательно говорит о наличие проблем. Полагаться в диагностике только на LA нельзя, его значения нужно учитывать только совместно с другими значениями. Поэтому переходим к следующей интересующей нас строке: Cpu.
Параметр Cpu

Строка Cpu показывает сразу несколько параметров нагрузки:
| us (user) | Использование процессора пользовательским процессами |
| sy (system) | Использование процессора системным процессами |
| ni (nice) | Использование процессора процессами с измененным приоритетом с помощью команды nice |
| id (idle) | Простой процессора. Можно сказать, что это свободные ресурсы |
| wa (IO-wait) | Говорит о простое, связанным с вводом/выводом |
| hi (hardware interrupts) | Показывает сколько процессорного времени было потрачено на обслуживание аппаратного прерывания |
| si (software interrupts) | Показывает сколько процессорного времени было потрачено на обслуживание софтверного прерывания |
| st (stolen by the hypervisor) | Показывает сколько процессорного времени было «украдено» гипервизором |
Не будем углубляться в анализ значений hi и si в этой статье, поскольку проблемы с прерываниями встречаются очень редко. Скажем только, что наиболее вероятная причина высоких значений данных параметров — проблема с кодом, ядром или DDoS-атака.
Рассмотрим подробнее остальные параметры Сpu.
Нагрузка на процессор (параметры sy, us, ni)
Высокие значения sy, us и ni самые понятные и простые для диагностики, поскольку показывают нагрузку на CPU, создаваемую запущенными программами. Смотрим в выводе команды top процессы по столбцу %CPU и оптимизируем их при необходимости. Либо просто добавляем мощность CPU на сервер.
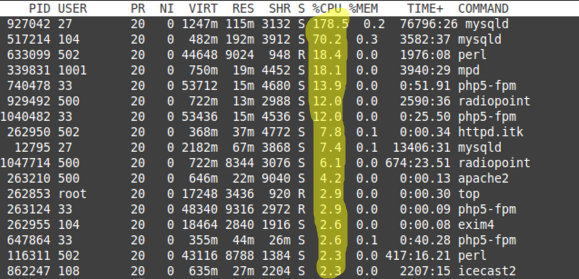
Однако надо учитывать, что однопоточные процессы будут выполнятся только на одном ядре. В этом случае даже при невысоком общем us могут наблюдаться проблемы.
Также нужно добавить, что высокое значение ni не всегда будет отрицательно влиять на работоспособность сервера. Возможно, приоритет процессов был понижен специально, чтобы они выполнялись только в том случае, когда процессор будет свободен. Данные процессы не оказывают влияния на работу системы. Например, это могут быть процессы создания бекапов.
Пример диагностики проблем при высоком us и sy
На сервере top показывает следующие значения:
CPU: 21.0% user, 0.0% nice, 74.6% system, 0.0% interrupt, 4.4% idle PID USERNAME THR PRI NICE SIZE RES STATE C TIME WCPU COMMAND 95383 mysql 37 4 0 227M 74388K sbwait 1 0:00 49.80% mysqld 96904 qhost 1 97 0 171M 31884K CPU1 1 0:04 7.08% httpd 97360 frekbok 1 97 0 185M 42464K RUN 0 0:02 7.08% httpd 97442 frekbok 1 97 0 178M 37196K RUN 2 0:01 5.18% httpd 97423 frekbok 1 -4 0 178M 37160K RUN 1 0:01 4.79% httpd 97439 frekbok 1 97 0 178M 37052K RUN 2 0:01 4.79% httpd 97411 frekbok 1 -4 0 178M 37148K RUN 3 0:01 4.69% httpd 97418 frekbok 1 97 0 178M 37168K RUN 0 0:01 4.59% httpd 97444 frekbok 1 -4 0 178M 37192K RUN 1 0:01 4.59% httpd 97416 frekbok 1 -4 0 178M 37052K RUN 2 0:01 4.49% httpd 97421 frekbok 1 -4 0 178M 37060K CPU0 0 0:01 4.39% httpd 97424 frekbok 1 97 0 178M 37304K RUN 2 0:01 4.30% httpd
При этом LA больше 100.
Явно видно, что проблемы в нехватке CPU для работы mysql, и в большом количестве http-соединений пользователя frekbok.
Заходим к пользователю frekbok и смотрим лог apache. Там видим такие POST-запросы, и множество им подобных:
76.164.234.170 - - [18/Sep/2015:06:10:41 +0400] "POST /component/k2/ HTTP/1.0" 200 59 "Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko" 76.164.234.170 - - [18/Sep/2015:06:10:41 +0400] "POST /component/k2/ HTTP/1.0" 200 59 "Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko" 76.164.234.170 - - [18/Sep/2015:06:10:43 +0400] "POST /component/k2/ HTTP/1.0" 200 59 "Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko"
По результату анализа логов можно сделать вывод, что проблема в китайских ботах, которые постят рекламу в комментарии на сайте. Ставим капчу на комментирование или отключаем комментарии, чистим БД. Проблема решена.
Определение оверселлинга (параметр st)
Параметр st интересен для виртуальных машин. Можно сказать, что он отображает оверселлинг CPU на родительской ноде. Он будет отличаться от 0 в случае, если VDS требуется процессор, но гипервизор не может выделить CPU, так как он используется в данный момент другими VDS. В случае, если данный параметр принимает большие значения на вашей VDS (ориентировочно более 5-10% совместно с высоким LA) и это мешает вашей работе, то остается только написать в техподдержку с просьбой перенести VDS на другую ноду.
Нагрузка ввода-вывода (параметр wa)
Самый интересный показатель это wa. На современных серверах мощности процессора и памяти обычно хватает, а большинство проблем связаны с операциями ввода/вывода.
Высокие значения wa, а также высокий LA, обычно говорят о простое процессов в состоянии D-state, связанном с дисковой подсистемой или с сетевыми проблемами. Однако, нельзя забывать, что этот параметр относится ко всем операциям ввода/вывода. Например, на выделенном сервере это значение может вырасти при работе с USB-накопителем, ожидании ответа от сокета или быть вызвано другими причинами.
Упрощенная модель состояний в Linux
- D-state — состояние непрерывного сна (процессы, которые ожидают освобождения потока ввода-вывода)
- R-state — процесс активен в настоящее время (выполняется в данный момент)
- S-state — состоянии ожидания (sleeping), т.е. он ожидает какого-то события или сигнала
- Т-state — процесс приостановлен сигналом STOP или выполнением трассировки
- Z-state — «зомби», процесс, завершивший свое выполнение, но присутствующий в системе, чтобы дать родительскому процессу считать свой код завершения
Посмотреть состояние процессов в системе можно с помощью команды ps с опциями: ps aux
По практическому опыту, заметные проблемы начинаются при wa больше 10-30%. Нужно понимать, что большое значение этого параметра не всегда свидетельствует о проблемах. Но желательно установить причину такого поведения и по возможности исправить ситуацию.
Пример нахождения причин высокого wa и load average
Смотрим командой ps aux | grep D процессы в состоянии D.
102 628884 0.0 0.0 97308 2432 ? D 13:08 0:00 /usr/sbin/exim4 -bd -q30m 102 628885 0.0 0.0 97308 2432 ? D 13:08 0:00 /usr/sbin/exim4 -bd -q30m 102 628886 0.0 0.0 97308 2432 ? D 13:08 0:00 /usr/sbin/exim4 -bd -q30m 102 628887 0.0 0.0 97308 2424 ? D 13:08 0:00 /usr/sbin/exim4 -bd -q30m 102 628888 0.0 0.0 97308 2424 ? D 13:08 0:00 /usr/sbin/exim4 -bd -q30m 102 628890 0.0 0.0 97308 2424 ? D 13:08 0:00 /usr/sbin/
Видим, что в состоянии ожидания висит множество процессов exim4. Скорее всего сервер был взломан и с него массово рассылают спам. Останавливаем exim и находим источник рассылки.
В случае, если у вас несколько VDS на ноде и необходимо найти источник нагрузки, нужно найти ту, с которой рассылается спам. Для этого можно использовать команду tcpdump -n | grep "smtp", с помощью неё мы проанализируем почтовый трафик на порту 25, и обнаружим IP-адрес с которого выполняется рассылка спама.
Нужно знать, что высокий wa внутри VDS, не всегда означает проблемы внутри контейнера. Проблемы также возможны на «родительской» ноде. Например, на ней не хватает I/O диска для всех VDS. Поэтому ваши процессы попадают в состояние ожидания. В таком случае нужно создать тикет в тех поддержку.
Нагрузка ввода-вывода: копаем глубже (atop)
Удобный инструмент для определения причин нагрузки — это atop c опциями: atop -l -c -d1
Однако, дальнейшее описание в первую очередь будет относится к VDS на виртуализации KVM и выделенным серверам. На виртуализации OpenVZ мы не сможем воспользоваться полными возможности данной утилиты, и скорее всего вам придется обратиться в тех. поддержку.
Рассмотрим его вывод:
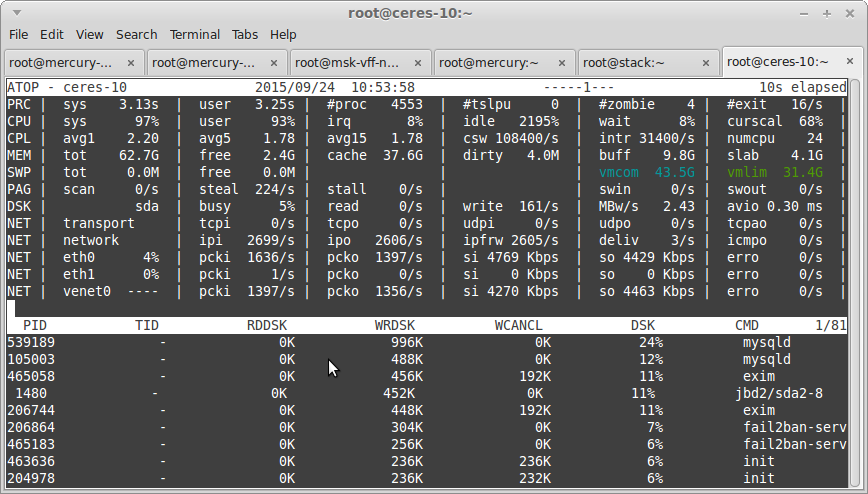
В строке DSK мы видим использование диска в данный момент. В строке busy в процентах указывается примерно сколько «ресурсов» диска потребляется в данный момент. Если там будет значение около 100% значит на диске, скорее всего, наблюдаются проблемы с операциями ввода/вывода. В случае использования VDS, данной строки может не быть и пугаться не стоит.
В нижней части видим список процессов, которые в данный момент выполняют дисковые операции. Вверху списка будут процессы, потребляющие больше всего ресурсов.
Как мы видим, процесс с идентификатором pid 539189 в данный момент ведет активную запись на диск. Узнать в какие файлы пишет данные этот процесс можно с помощью команды lsof.
Вызов команды lsof -p539189 (подставляем pid-идентификатор нужного процесса) показал такой результат:
mysqld 539189 110 4u REG 182,374993 0 12516 (deleted)/tmp/ib30lihW lsof: no pwd entry for UID 110 mysqld 539189 110 5u REG 182,374993 0 12520 (deleted)/tmp/ibSrHvsH lsof: no pwd entry for UID 110 mysqld 539189 110 6u REG 182,374993 0 12522 (deleted)/tmp/ibLkoJDs lsof: no pwd entry for UID 110 mysqld 539189 110 7u REG 182,374993 0 12524 (deleted)/tmp/ibNk007Y
Видно, что данный процесс mysql пишет временные файлы на жесткий диск и этим создает нагрузку. Поэтому желательно провести его оптимизацию.
Более подробно проанализировать нагрузку на дисковую систему можно также с помощью специализированной утилиты iotop.
Заключение
В данной статье мы рассказали о малой части средств для мониторинга нагрузки на серверах. И даже в них мы охватили минимум возможностей. Для более полного знакомства с возможностями описанных утилит, читайте документацию (ссылки в статье на названиях команд). Но даже описанных в статье возможностей хватает для диагностики большинства возникающих проблем.

