Нейросети за 3 года стремительно шагнули от «вау, будущее!» к обычной рутине голосовых помощников, генераторов контента и рекомендательных алгоритмов в соцсетях.
Большинство считает, что создать нейросеть под силу только узкоспециализированным экспертам. Это не совсем так — с помощью языка Python и библиотек разработать и обучить свою модель искусственного интеллекта нейросеть проще, чем кажется.
Руководство подойдет всем, кто хочет погрузиться в мир машинного обучения. Начинаем!
Что такое нейросеть и как она работает
Нейросеть — это математическая модель, вдохновлённая принципами работы человеческого мозга. Она способна обучаться на данных, выявлять сложные закономерности и принимать решения без явного программирования.
Что нужно знать о базовых компонентах нейросети:
- Искусственные нейроны — это аналоги биологических нейронов, они получают входные данные, обрабатывают их и передают дальше.
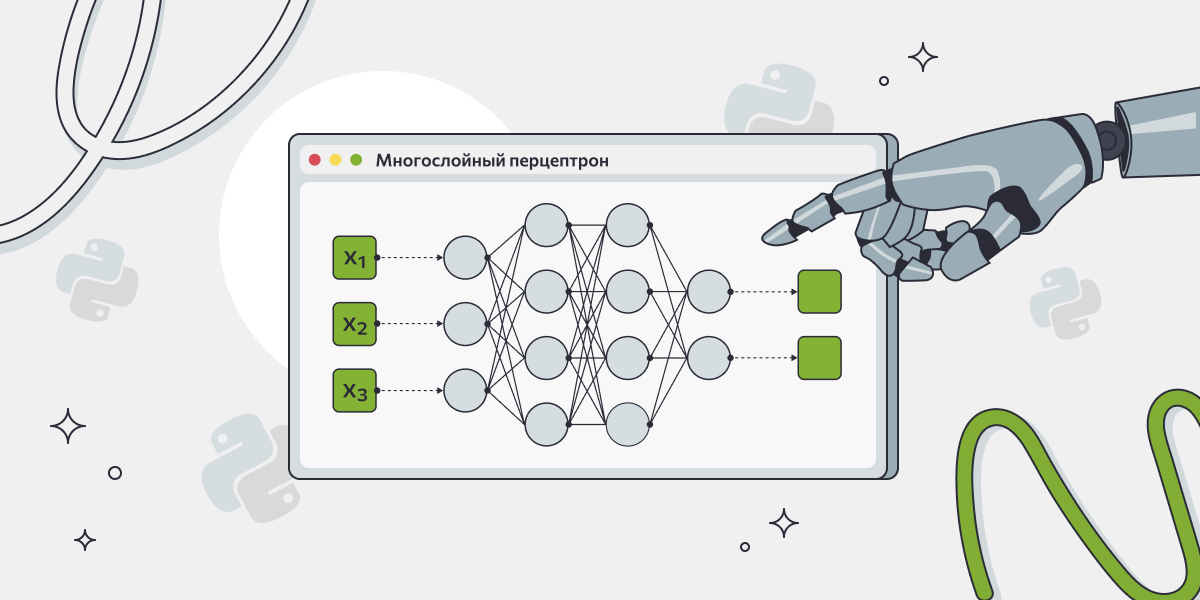
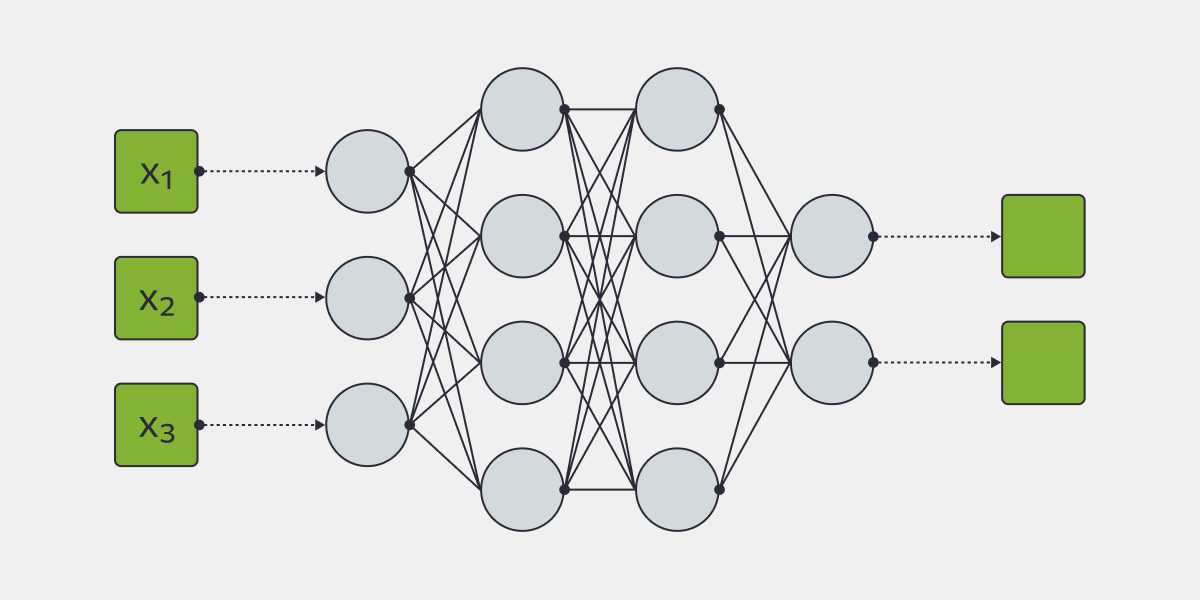
- Слои нейросети — это «стенки» из нейронов. Слоев в каждой нейросети не менее трех: входной (получает исходные данные), скрытый (один или несколько — они выполняют основную обработку информации) и выходной (выдает конечный результат — классификацию, прогноз и т. п.)
- Весовые коэффициенты (веса) — определяют силу влияния каждого нейрона на следующий.
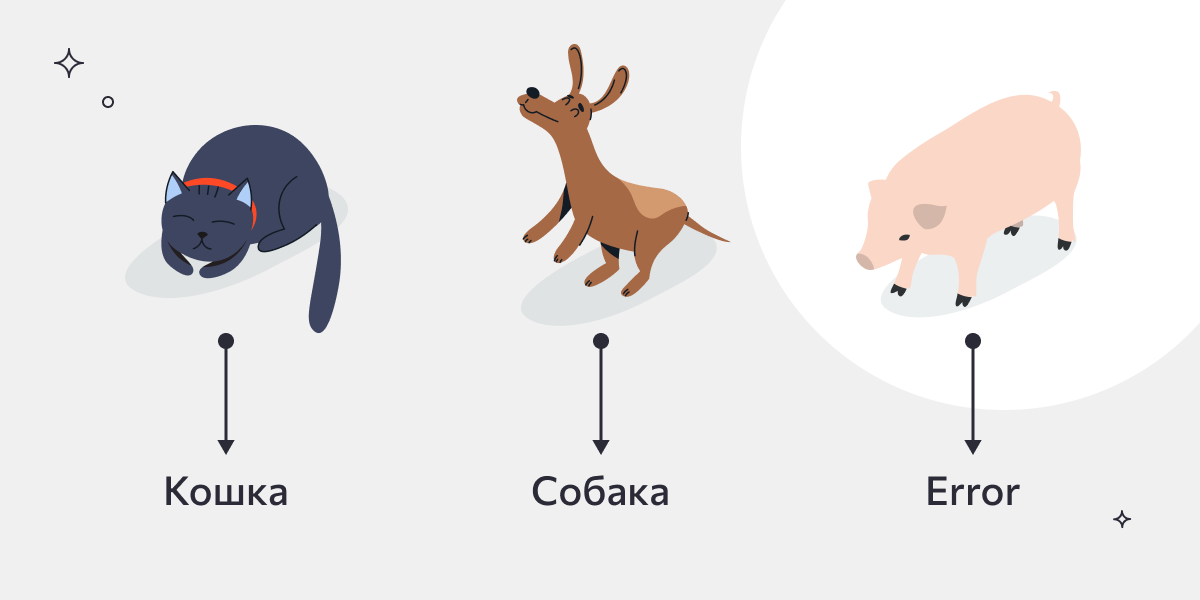
Допустим, мы хотим, чтобы нейросеть могла определять, кто изображен на картинке: кошка или собака. Обучение модели начинается с того, что ей подается тысяча изображений с этими животными. В результате она учится распознавать именно такие объекты, но при этом не знает ничего о существовании других животных.
Следующий этап – тестирование. В модель загружают изображения, которых она еще не видела, и предлагают определить, кто на них.
Например, на входе мы подаем 3 изображения (х1, х2 и х3) и просим определить, кто на них — кошка или собака (напоминаем, что третьего варианта нет).
Нейросеть распознает изображение и разбивает его на детали, отделяет объект от фона, определяет характерные особенности. На каждом слое перцептрона происходит анализ и переход на следующий слой в соответствии с весами нейронов слоя:
- на x1 она определяет мягкие уши под определенным наклоном к голове, плоский нос, полосатую шерсть и сообщает нам, что на х1 изображена кошка;
- на x2 уши другой формы, широкая пасть, характерная стойка и хвост кольцом. Результат: на х2 – собака;
- на x3 уши напоминают кошачьи, но тело слишком крупное, нос — пятачком, хвост маленький и крючком. Люди сразу узнали бы свинью, но наша нейросеть обучена распознавать только собаку и кошку, так что она выдает результат, что на x3 — неизвестный объект/ошибка.
Важно! Мы не программируем нейроны на определенные действия. Всё, что происходит на скрытых слоях, остается на скрытых слоях. Нейросеть сама определяет алгоритм работы. На то она и «умная» технология.
Типы нейросетей
Существуют разные типы нейросетей под разные задачи. Одни определяют объекты на изображениях, другие – строят классификации и прогнозы, третьи – генерируют тексты.
Функциональность нейросетей очень широка и, по сути, она стремится к повторению любых операций, на которые способен человеческий мозг. Каждая операция: определение, анализ, предположение — это отдельная функция, и для нее готовится отдельная нейросеть. Поэтому в одном приложении одновременно могут работать несколько нейросетей разных типов – каждая для своей операции.
Тип | Применение | Особенности |
|---|---|---|
Полносвязные (Dense) | Табличные данные: работа с личными данными, статистикой продаж, анализ клиентского поведения | Простая архитектура |
Сверточные (CNN) | Изображения: компьютерное зрение, определение объектов на фото, определение текста в pdf-файлах | Выделение ключевых признаков из массива данных |
Рекуррентные (RNN) | Текст, временные ряды: прогнозирование, построение дорожных сетей, генерация текстов, рекомендательные системы | Запоминание контекста |
Для знакомства с нейросетями подойдет первый тип (Dense) – они популярны для решения бизнес-задач, поэтому далее мы рассмотрим именно такой пример.
Подготовка к созданию нейросети: инструменты и датасет
Для иллюстрации мы возьмем бизнес-задачу распознавания любимых категорий товаров у покупателей интернет-магазина. Для этого у нас есть большая таблица с данными клиентов, в которую заносится информация о том, кто, когда и как совершает покупки.
ID клиента | Комплектующие материалы | Процессоры | Смартфоны | Смарт-часы | … | Дата рождения | Город |
|---|---|---|---|---|---|---|---|
1 | 15300 | 120200 | 95200 | 17340 | … | 13.05.1987 | Москва |
2 | 180000 | 1334200 | 274500 | 294000 | … | 03.03.2000 | Серпухов |
… | … | … | … | … | … | … | … |
Такая таблица обычно хранится во внутренней системе учета, CRM или 1С. Сначала мы обучим нейросеть на части этих данных, затем проведем тестирование и только после этого сможем внедрить в бизнес-процессы.
Прежде чем приступить к разработке нейросети, необходимо подготовить рабочую среду – IDE, где мы будем писать код. Например, PyCharm, VS Code или Jupiter Lab. Это как собрать мастерскую перед созданием сложного механизма: без правильных инструментов работа будет неэффективной, а то и вовсе невозможной.
Установка Python и необходимых библиотек
Python — фундамент, на котором мы будем строить нашу нейросеть. Этот язык программирования был выбран не случайно:
- Интуитивно понятный синтаксис, который легче освоить, чем многие другие языки.
- Огромное сообщество разработчиков и богатая экосистема.
- Специализированные библиотеки (готовые наборы кода) для машинного обучения.
Библиотеки, которые нам понадобятся:
- TensorFlow/Keras — база для работы с нейросетями:
- TensorFlow — вычислительное ядро и готовые реализации сложных алгоритмов;
- Keras (теперь интегрированный в TensorFlow) — удобный высокоуровневый API для быстрого создания моделей.
NumPy — основа всех вычислений в Python:
- Обеспечивает работу с многомерными массивами;
- Оптимизированные математические операции работают в десятки раз быстрее обычного Python.
Pandas — помощник в работе с данными:
- Удобные дата-фреймы (структуры данных) для хранения информации в таблицах;
- Мощные инструменты для очистки и предварительной обработки данных.
- Matplotlib/Seaborn — могут пригодится для визуализации данных и результатов.
Зачем такой набор инструментов?
Представьте, что вам нужно построить дом. Вы можете варить металл для гвоздей и валить лес самостоятельно (чистый Python), а можете использовать готовые стройматериалы и инструменты (библиотеки).
Например:
- без NumPy операции выполняются в сотни раз медленнее;
- без TensorFlow придется реализовывать алгоритмы работы с ошибками и галлюцинациями нейросети;
- без Pandas предварительная обработка данных займет в разы больше времени.
Установить все необходимые компоненты можно одной командой в терминале:
pip install tensorflow numpy pandas matplotlib seabornЭтот этап — основа всего последующего процесса. Далее мы подробно разберем, как выбрать подходящую архитектуру нейросети для нашей задачи.
Выбор типа нейросети под задачу
Рассмотрим наш пример для интернет-магазина.
Нам нужно:
- анализировать историю покупок клиентов;
- автоматически определять их предпочтения;
- выводить рекомендации в личном кабинете («любимые категории»).
Для нашей задачи выберем полносвязную нейросеть (Dense), так как:
- данные представлены в табличном виде (история покупок),
- нужно предсказывать несколько категорий одновременно,
- архитектура достаточно проста для первого проекта.
Такой выбор обеспечивает баланс между точностью предсказаний и простотой реализации, что и нужно для первого проекта. В следующих разделах мы подробно разберем процесс обучения и оптимизации этой модели.
Подготовка данных
Прежде чем нейросеть начнёт обучаться и выдавать рекомендации по «любимым категориям», необходимо тщательно подготовить данные. Этот процесс можно сравнить с подготовкой ингредиентов для сложного блюда — от качества обработки напрямую зависит конечный результат.
Что такое датасет
Это структурированный набор данных для обучения. В нашем случае:
- строки — клиенты,
- колонки — характеристики (сумма покупок по категориям, город, возраст и т. д.).
Пример датасета:
ID клиента | Комплектующие материалы | Процессоры | Смартфоны | Смарт-часы | … | Дата рождения | Город |
|---|---|---|---|---|---|---|---|
1 | 15300 | 120200 | 95200 | 17340 | … | 13.05.1987 | Москва |
2 | 180000 | 1334200 | 274500 | 294000 | … | 03.03.2000 | Серпухов |
… | … | … | … | … | … | … | … |
Подготовка данных будет проходить в несколько этапов:
- Сбор.
- Очистка.
- Нормализация.
- Разделение на выборки.
Рассмотрим каждый из них подробно.
Этапы подготовки
Сбор данных
Экспортируем нашу базу данных (таблицу с историей покупок) из CRM/1С в формате CSV. Далее нужно указать Python путь к файлу, с которым мы работаем, с помощью кода:
data = pd.read_csv('путь_к_файлу/данные.csv')Не забудьте сохранить исходный файл для аудита!
Очистка
Здесь будет три важных этапа.
Удаление аномалий (например, технические заказы для проверки функциональности):
clean_df = df[~df['user_email'].isin(test_users)]Заполнение пропусков (например, вы не знаете возраст некоторых покупателей, тогда можно заполнить пропуски медианным значением):
df['возраст'].fillna(df['возраст'].median(), inplace=True)Кодирование категорий — это нужно для перевода текстовых данных, например, название городов, в числа, поскольку машина не понимает, что такое «Москва», она поймет только что-то вроде:
city_encoder = LabelEncoder() df['город_код'] = city_encoder.fit_transform(df['город'])
Нормализация
Это процесс приведения числовых данных к единому масштабу (обычно в диапазон от 0 до 1), чтобы признаки одинаково влияли на модель машинного обучения.
Представьте, что вы учите нейросеть различать покупки. У вас есть два показателя:
- сумма чека (от 100 до 50 000 руб.),
- частота покупок (от 1 до 10 раз в месяц).
Нейросеть будет обращать больше внимания на «сумму», просто потому что эти числа больше. Это как сравнивать метры и сантиметры без перевода в одну единицу измерения.
Что дает нормализация:
- Все числа становятся в один масштаб (от 0 до 1).
- Нейросеть учится быстрее.
- Точность предсказаний повышается.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(raw_data)Разделение данных
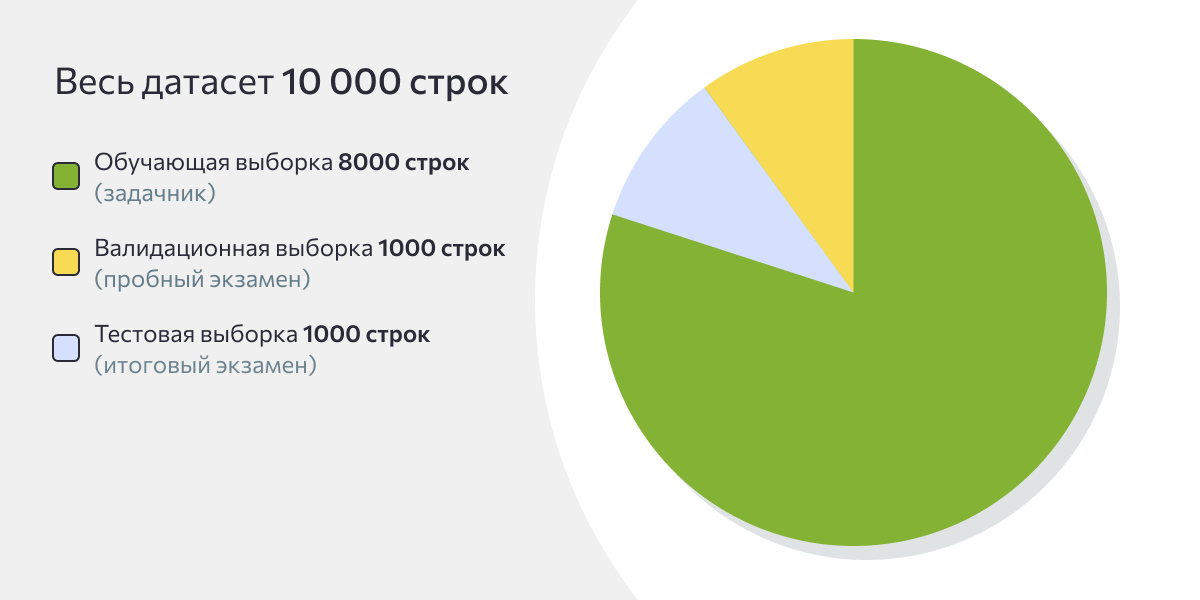
Этот этап нужен для того, чтобы позже проверить нейросеть в деле. Для этого мы изолируем часть записей внутри документа.
Примерные пропорции разделения:
- 80% — обучающая выборка, основной массив для обучения нейросети,
- 20% — тестовый набор, из них половина будет валидационной (контроль во время обучения), а другая половина — тестовой (полностью изолированные данные для объективной оценки).
# Разделение на признаки (X) и целевую переменную (y)
X = data.drop('favorite_category', axis=1)
y = data['favorite_category']
# Первичное разделение
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.2)
# Разделение временных данных на validation и test
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5)Визуализация разделения данных представлена на круговой диаграмме:
Пошаговое создание нейросети для определения «любимых категорий товаров»
Инструкция включает четыре шага.
Шаг 1: Создаём архитектуру нейросети
Представьте, что вы проектируете «мозг» для вашей системы рекомендаций. Как импульсы проходят через разные этапы и стимулируют умозаключения, так же и мы будем проектировать структуру нейросети.
Основные компоненты включают:
- Входной слой (органы чувств):
- Принимает данные о покупках (10-15 параметров: суммы, частоты, категории).
- Скрытые слои (мыслительные центры):
- Первый скрытый слой: 128 нейронов для первичного анализа.
- Второй скрытый слой: 64 нейрона для углубленной обработки.
- Функции активации ReLU — «включают» только значимые признаки.
- Выходной слой (принятие решения):
- 5 нейронов (по числу основных категорий товаров);
- Функция softmax преобразует данные в вероятности (сумма = 100%).
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([
Dense(128, activation='relu', input_shape=(15,)),
Dense(64, activation='relu'),
Dense(5, activation='softmax')
])Почему такая структура?
- 128 → 64 нейрона: постепенное сжатие информации,
- ReLU обеспечивает лучшую производительность для подобных задач,
- Softmax: идеален для многоклассовой классификации.
В итоге мы получаем мыслящую систему, где данные могут проходить путь от восприятия до умозаключения через несколько аналитических слоев. Теперь нам нужно задать правила, чтобы обучить нейросеть.
Шаг 2: Настраиваем процесс обучения
Теперь укажем нейросети «правила мышления» с помощью нескольких команд в коде.
Оптимизатор – алгоритм настройки параметров связи между нейронами:
Adam — «золотой стандарт» (адаптирует скорость обучения);
параметры по умолчанию работают в 90% случаев.
Функция потерь – мера измерения ошибки:
categorical_crossentropy — измеряет расхождение между предсказанием и реальностью;
особенно хороша для задач типа «один из многих» (5 категорий товаров).
Метрики качества – способы измерения успешности обучения:
Accuracy — процент верных предсказаний,
Precision — точность по каждому классу,
Recall — полнота распознавания категорий.
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy', 'Precision', 'Recall']
)Шаг 3: Процесс обучения нейросети
Итак, мы собрали «мозг» (архитектуру) и дали ему «правила игры» (оптимизатор и функцию потерь). Теперь настало время тренировать его нашими данными, но, чтобы нейросеть училась эффективно и не перетренировалась или не наделала ошибок, необходимо правильно настроить сам процесс.
Настройка параметров обучения. Среди них:
- Эпохи (epochs=20) — полные циклы обработки всех данных, столько раз нейросеть проходит по всем ячейкам таблицы, чтобы понять принципы. 20 эпох обычно достаточно для сходимости модели без переобучения. Сходимость предполагает минимальный процент ошибок при проверке результатов (не всегда нулевой).
- Размер пакета (batch_size=32) — количество примеров, которые анализирует нейросеть перед корректировкой весов. 32 – оптимальное число примеров для одновременной обработки, чтобы работать эффективно, но не перегружать память.
- Валидационные данные (validation_data) — 10% данных, которые модель видит только во время проверок, своеобразные контрольные работы для нейросети.
Мониторинг обучения. Для этого определяем следующие ключевые метрики для отслеживания:
- Точность на обучающих данных — как хорошо модель запоминает паттерны.
- Точность на валидации — как хорошо обобщает знания.
- Значение функции потерь — величина ошибки предсказаний.
history = model.fit(
x_train,
y_train,
epochs=20,
batch_size=32,
validation_data=(x_val, y_val)
)После этого можно запускать интерпретатор и ждем, когда нейросеть пройдет все эпохи. Когда это произойдет, можно говорить о том, что нейросеть прошла обучение и можно запускать тестирование.
Шаг 4: Финальное тестирование модели
Ранее мы разделили датасет на обучающую (80%), валидационную (10%) и тестовую (10%) выборки. Первые две мы использовали для обучения нейросети, настало время проверить, что усвоила нейросеть. Для этого нам и нужна тестовая выборка — она выступает в роли независимых данных (10% от исходного набора). С ней мы проводим те же манипуляции, что и с обучающей: нормализация, кодирование категорий и другие преобразования. И смотрим, какой результат она выдает.
Для комплексной оценки результата можно использовать этот скрипт:
# Загрузка и подготовка данных"
test_data = pd.read_csv('test_clients.csv')
X_test = preprocess_data(test_data)
y_test = test_data['preferred_category']
# Оценка модели
test_loss, test_acc, test_prec, test_rec = model.evaluate(X_test, y_test)
# Развернутый отчет
print("\n" + "="*50)
print("ФИНАЛЬНАЯ ОЦЕНКА МОДЕЛИ")
print("="*50)
print(f"Точность: {test_acc*100:.1f}%")
print(f"Точность по категориям: {test_prec*100:.1f}%")
print(f"Полнота распознавания: {test_rec*100:.1f}%")
# Примеры предсказаний
sample_predictions = model.predict(X_test[:5])
for i, pred in enumerate(sample_predictions):
print(f"\nКлиент {i+1}:")
print(f"Факт: {y_test.iloc[i]}")
print(f"Прогноз: {categories[np.argmax(pred)]}")
print(f"Уверенность: {np.max(pred)*100:.1f}%")
print("Топ-3 варианта:")
for j in np.argsort(pred)[-3:][::-1]:
print(f"- {categories[j]}: {pred[j]*100:.1f}%")На выходе мы получаем несколько два типа результатов:
- Объект
history– это дневник тренировок нашей нейросети; - Результат метода
model.evaluate()– это итоговая оценка на выпускном экзамене.
Давайте разберем, как подробно прочитать эти результаты, а главное, что с ними делать дальше
Анализ объекта history
Во время обучения на каждом этапе (эпохе), нейросеть записывает свои результаты – это что-то вроде самостоятельных работ в школе.
Эпоха 1/20
250/250 - 3s - loss: 1.5432 - accuracy: 0.3010 - val_accuracy: 0.3510
...
Эпоха 20/20
250/250 - 1s - loss: 0.3210 - accuracy: 0.8915 - val_accuracy: 0.8650Для нас здесь важны два параметра – accuracy и val_accuracy, то есть точность на обучающей и валидационной выборках. Они показывают, как модель постепенно учится выявлять закономерности и справляться с новыми для себя данными. Мы предполагаем, что эти параметры от раза к разу будут расти, что и наблюдаем в примере выше: в первой эпохе они составляют 0.3010 и 0.3510. К двадцатой эпохе это уже 0.8915 и 0.8650, что можно округлить — 89% и 87%, соответственно.
Нужно стремиться к постепенному росту и сближению этих параметров.
Точность 85-90% говорит об успешной сессии обучения, а разрыв между ними менее 5% – признак хорошей обобщающей способности.
Результат метода model.evaluate()
Если продолжить аналогию со школьной жизнью, то метод model.evaluate() — это выпускной экзамен.
На выходе обычно мы получаем такой вид и примеры анализа:
ФИНАЛЬНАЯ ОЦЕНКА МОДЕЛИ
==================================================
Точность (Accuracy): 85.2%
Точность по категориям (Precision): 70.5%
Полнота распознавания (Recall): 83.8%
Клиент 1:
Факт: Электроника
Прогноз: Электроника
Уверенность: 92.5%
Топ-3 варианта:
- Электроника: 92.5%
- Книги: 4.1%
- Комплектующие материалы: 2.1%
Клиент 2:
Факт: Смартфоны
Прогноз: Комплектующие материалы
Уверенность: 51.3%
Топ-3 варианта:
- Комплектующие материалы: 51.3%
- Смартфоны: 48.2%
- Процессоры: 0.5%
…Что это значит для бизнеса:
- Точность определения
Accuracy85,2% – значит, что нейросеть способна правильно определить любимые категории у 85 человек из 100 на основе их истории покупок. Это открывает большой простор для рекомендаций, персонализированных предложений и т. п. - Точность по категориям
Precision70,5% – когда нейросеть говорит «Этот клиент часто покупает электронику», она права в 70% случаев. Это снижает риск отправки нерелевантных предложений. - Полнота
Recall83,8% – модель способна найти 83% всех реальных любителей каждой категории. Это значит, что мы отследим большинство заинтересованных кандидатов и сможем прогнозировать спрос.
Для демонстрации нейросеть предоставила нам результаты по каждому клиенту тестовой выборки. Рассмотрим их подробно:
- Клиент 1 – модель уверенно и правильно предсказала категорию. Ему сразу можно показывать новинки электроники.
- Клиент 2 – модель ошиблась, но её уверенность и так была невысокой (51% против 48%). Клиент покупает и то, и другое одинаково часто. В таких случаях можно настроить не автоматическую рассылку рекомендаций, а уточняющее действие («Что вам интереснее?») или показать баннеры с двумя категориями и посмотреть отклик.
Что делать, если результаты плохие? Мы не можем предусмотреть абсолютно все варианты просчетов, но вот самые популярные проблемы и способы их решения:
- Точность <70% — добавьте больше данных (для этого можно внедрить более детальную аналитику, пополнить таблицу историческими данными или использовать внешние датасеты с анализом рынка).
- Если система ошибается в конкретных категориях, проверьте баланс данных и пополните бедные категории.
Затем пройдите заново все этапы и добивайтесь того, чтобы точность стала выше 85%. После этого можно переходить к внедрению.
Что делать дальше
Итак, теперь у вас есть готовая обученная на ваших данных нейросеть, которую можно внедрять в работу. С точностью ~85% модель уже можно интегрировать в CRM-систему для персонализации email-рассылок, рекомендаций на сайте и таргетирования рекламы.
Возможность смотреть «Топ-3 варианта» позволяет создавать более гибкие и умные бизнес-процессы и готовить стратегию развития, не полагаясь слепо на единственный прогноз. Также вы можете продолжать совершенствовать свою модель – дополнять данные, усложнять архитектуру, пробовать новые алгоритмы и т.д.
Создать и внедрить нейросети в бизнес-процессы — задача нетривиальная. Нужно разбираться в данных, настраивать алгоритмы, тестировать и дорабатывать модель. На первых порах это может казаться чем-то запредельно сложным, но хорошая новость в том, что нейросети — это не магия, а технология, которую можно освоить.
Да, на старте можно (и даже нужно) обратиться к специалистам, которые помогут с реализацией. Но даже если вы не работаете напрямую с кодом, базовое понимание принципов работы нейросетей даст вам ключевые преимущества.





