Графические процессоры (GPU) могут обрабатывать большие объёмы данных, поэтому их применение уже давно вышло за рамки игровой индустрии. С их помощью обучают нейросети, создают сложные визуализации и анализируют данные во многих отраслях. Разберём подробнее, как работает GPU, чем он отличается от CPU, какие бывают виртуальные решения и для чего они нужны.
Что такое GPU и как он работает
GPU (Graphics Processing Unit) — это графический процессор, специализированный вычислительный чип, оптимизированный для параллельной обработки больших объёмов однотипных данных. Он особенно эффективен при работе в сценариях, в которых задачу можно разбить на большое количество независимых вычислений.
Принцип работы GPU определяется его архитектурой. Графический процессор размещается на дискретной плате — видеокарте, и имеет собственные чипы памяти и подсистему питания. Внутри графический процессор состоит из таких компонентов:
- Вычислительные ядра — выполняют основной объём математических операций. Если в современном серверном CPU (центральном процессоре) — до 128–192 мощных производительных ядер, то у GPU — тысячи более простых вычислительных блоков.
- Видеопамять (VRAM и внутренний кэш) — хранит данные, с которыми работает графический процессор: текстуры, элементы сцены, параметры моделей, промежуточные результаты вычислений. При этом прямо внутри чипа, у каждой группы ядер, есть собственная локальная разделяемая память и сверхбыстрый L1-кэш для мгновенного доступа к текущим задачам.
- Подсистема памяти и обмена данными — обеспечивает высокую пропускную способность, чтобы одновременно снабжать информацией огромное количество ядер. Поскольку тысячи вычислительных блоков параллельно обрабатывают колоссальные массивы данных, объёма внутреннего кэша им не хватает. Поэтому GPU делает ставку на очень широкую шину памяти, которая позволяет мгновенно прокачивать огромные потоки данных из VRAM в чип и обратно.
- Блоки управления и планирования — распределяют задачи между тысячами ядер, следят за очерёдностью вычислений и поддерживают непрерывную, максимальную загрузку всех вычислительных ресурсов.
Работа GPU строится на модели SIMT (Single Instruction, Multiple Threads) — одна инструкция, множество потоков. Задача разбивается на тысячи мелких независимых потоков. Например, при обработке изображения каждый поток может отвечать за расчёт цвета одного конкретного пикселя.
При этом вычислительные блоки GPU почти никогда не простаивают. Если одна группа задач ждёт данные из памяти, GPU мгновенно переключает ресурсы на выполнение другой, у которой данные уже готовы. Это можно сравнить с работой большого офиса: пока один сотрудник ждёт документы, другой продолжает выполнять свою часть задачи, и общий процесс не останавливается.
В чём разница между GPU и CPU
Главное различие между центральным процессором и графическим — в способе обработки данных. CPU и GPU изначально проектировались для разных задач, поэтому отличаются архитектурой и принципами работы с кэшем и памятью.
Различие в устройстве ядер. CPU эффективно использовать для последовательной обработки операций и постоянного переключения между разными типами нагрузки. В свою очередь, GPU рассчитан на другой тип нагрузки: когда большую задачу можно разбить на множество однотипных операций и выполнить их одновременно.
Разница в устройстве кэш-памяти. Кэш — это сверхбыстрая память, встроенная прямо в процессор, которая позволяет CPU или GPU не обращаться каждый раз к медленной памяти: ОЗУ или VRAM. Однако CPU и GPU работают с кэшем по-разному:
- У CPU кэш огромен и имеет сложную трёхуровневую структуру (L1, L2, L3). Задача CPU — сделать так, чтобы конкретное ядро получило нужные данные мгновенно, без задержек.
- У GPU иная иерархия. Его общий L2-кэш меньше, чем у CPU, а L1-кэш разделён между отдельными кластерами ядер. GPU не пытается дать суперскорость одному конкретному ядру, мгновенно переключает работу на другую тысячу ядер, у которых данные уже под рукой.
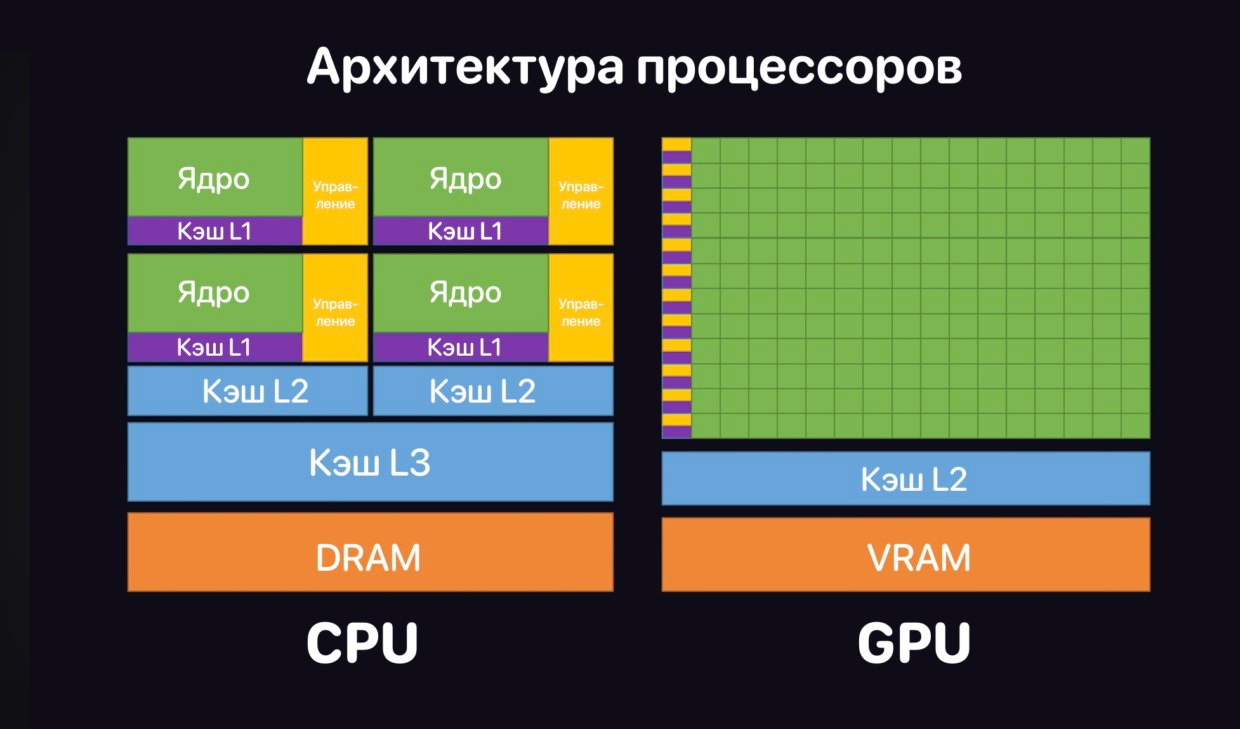
Разница в работе с оперативной памятью. Разный подход к вычислениям требует и разного типа внешней памяти.
- CPU работает с системной RAM, например, DDR4/DDR5. Она оптимизирована под минимальное время отклика (низкую задержку). Шина памяти (канал обмена данными) здесь относительно узкая (обычно 64–128 бит), но данные по ней долетают до процессора практически мгновенно.
- GPU работает с видеопамятью VRAM, например, GDDR6 или HBM. Ему нужно одновременно снабжать данными тысячи прожорливых ядер. Поэтому GPU делает ставку на сверхширокую шину памяти (от 256–384 бит до нескольких тысяч бит в HBM). Задержка старта передачи данных здесь чуть выше, чем у CPU, но за один такт GPU может прокачать колоссальный массив информации.
Именно поэтому центральный процессор управляет логикой приложений, работой операционной системы, сетевыми запросами, файлами и всеми основными процессами сервера. А графический берёт на себя рендеринг, обработку видео, аналитику больших массивов данных и машинное обучение.
Архитектурные различия между CPU и GPU влияют на два важных параметра:
- Латентность (задержка). Задача CPU — мгновенно переключаться между процессами и выполнять их последовательно, чтобы как можно быстрее обработать отдельную операцию.
- Пропускная способность. GPU предполагает, что данных очень много, и они однотипны, поэтому он не фокусируется на отдельных процессах, чтобы за один такт обработать как можно больше операций.
Условно CPU можно сравнить со специалистом, который сам последовательно разбирает большую задачу шаг за шагом. GPU — это целый отдел, где ту же задачу заранее делят на множество небольших одинаковых фрагментов и распределяют между исполнителями. За счёт этого работа идёт не по очереди, а одновременно, поэтому общий результат получается быстрее — но только в тех случаях, когда задачу действительно можно распараллелить.
Для каких задач используют серверы с GPU
Основная сфера применения GPU-серверов — задачи, требующие огромного количества однотипных математических операций. GPU не заменяет центральный процессор, а дополняет его. Если CPU — это мозг системы, который управляет сложной логикой и поочерёдными командами, то GPU — это мускулы для тяжёлой однотипной работы.
Формально любую задачу можно выполнить за счёт CPU или GPU. Но если задача связана с обработкой массивов данных, визуализацией или ИИ, центральный процессор будет работать неделями, а графический — справится за несколько минут.
В серверном сегменте GPU применяются везде, где требуется высокоскоростная параллельность.
Искусственный интеллект и машинное обучение (AI/ML). GPU — фундамент для всех этапов работы с нейросетями. Чтобы модель могла эффективно распознавать образы или анализировать текст, ей необходимо обработать колоссальные датасеты. Этот процесс требует выполнения множества параллельных операций по настройке внутренних параметров сети, с чем GPU справляется лучше, чем CPU.
Когда обученная модель (например, чат-бот или система распознавания лиц) отвечает пользователю, GPU обеспечивает минимальный отклик (latency), что критично для высоконагруженных сервисов. Обработка через GPU в таком случае сокращает время на размышление нейросети и сокращает время между запросом и ответом.
Аналитика больших данных (Big Data). Благодаря актуальным библиотекам, например, NVIDIA RAPIDS, обработку данных можно перенести из классических баз данных и Python-скриптов (Pandas) на ядра GPU. Это ускоряет подготовку данных для аналитики в 10–50 раз, что повышает эффективность антифрод-систем в банках, расчёт логистических цепочек в ритейле или анализ поведения миллионов пользователей в реальном времени.
Рендеринг и компьютерная графика (CGI). Производство визуального контента — это родная стихия GPU. Они используются при создании кадров в кино и анимации для GPU-рендеринга. Дизайнеры могут увидеть результат почти мгновенно, не дожидаясь многочасового просчёта на CPU-фермах.
VDI: удалённые рабочие столы. Обычные облачные рабочие столы плохо справляются с тяжёлым софтом. Серверы с GPU позволяют развернуть виртуальные машины для специалистов, работающих удалённо. Это может быть полезно для инженеров при работе в AutoCAD, Revit, SolidWorks или для дизайнеров — в пакете Adobe (Photoshop, Premiere).
Научные исследования и моделирование (HPC). Высокопроизводительные вычисления в науке опираются на GPU для симуляции физических процессов.
- В фармацевтике — при моделировании молекулярных связей для создания новых лекарств.
- В геофизике — для обработки данных сейсморазведки для поиска месторождений нефти и газа.
- В метеорологии — при прогнозировании погоды и климатических изменений.
Стриминг и облачный гейминг. Здесь GPU отвечает и за графику, и за аппаратное сжатие видеопотока (NVENC). Графический процессор берёт на себя обработку игрового потока на стороне сервера и передачу готовой картинки пользователю.
Для стриминговых платформ и сервисов видеонаблюдения GPU незаменимы при перекодировании видео в разные разрешения (multi-bitrate) в режиме реального времени. Аппаратные энкодеры в GPU позволяют обрабатывать десятки видеопотоков 4K одновременно на одном узле.
Виды GPU: десктопные или профессиональные
При аренде сервера вы столкнётесь с двумя типами ускорителей: десктопными и профессиональными. Разница между ними — в сценариях использования.
Десктопные. Такие видеокарты отлично показывают себя, когда нужна максимальная мощность за разумные деньги. Благодаря высокой частоте ядра в задачах рендеринга или обучения небольших моделей они могут работать даже быстрее некоторых профессиональных решений.
Пользовательские (десктопные) GPU подходят, когда нужно быстро отрендерить видео, запустить игру на облачном сервере или поработать с нейросетями, не требующими огромного объёма памяти. Поэтому GPU часто используют геймеры, видеомонтажёры, 3D-дизайнеры и небольшие ИИ-стартапы.
Профессиональные. Это специализированные устройства, созданные для бесперебойной работы в составе крупных серверных кластеров. Профессиональное оборудование чаще всего выбирают крупный бизнес, Data Science команды, государственные и научные проекты.
Сильные стороны:
- Объём и тип памяти. Профессиональные карты часто оснащаются памятью с коррекцией ошибок (ECC). Это критично для научных расчётов, где даже одна случайная ошибка в бите данных может испортить результат многодневного вычисления.
- Масштабируемость. Эти карты поддерживают технологии (например, NVLink), которые позволяют объединять несколько GPU в один сверхмощный вычислительный узел.
- Долговечность и поддержка. Они рассчитаны на экстремальные нагрузки в режиме 24/7 годами и имеют драйверы, сертифицированные для работы в сложном инженерном ПО.
Профессиональные GPU могут тянуть обучение тяжёлых LLM-моделей (как ChatGPT), работу с Big Data. Также они в приоритете, когда нужны точные расчёты.
Выбор между десктопными и профессиональными GPU зависит от задачи. Если ваша цель — максимальная скорость при ограниченном бюджете, десктопные видеокарты станут отличным выбором. Если же вам важна отказоустойчивость, работа с гигантскими объёмами данных и объединение серверов в кластеры, стоит смотреть в сторону профессиональных решений.
GPU Passthrough и vGPU: что это такое и как облегчает доступ к мощным графическим процессорам
Определиться с моделью видеокарты — это только половина дела. Чтобы GPU стабильно работал, ему необходимо обеспечить соответствующую инфраструктуру. Но не обязательно держать дома или в офисе дорогостоящее оборудование — можно арендовать готовый виртуальный сервер (VDS/VPS) с GPU у хостера.
В зависимости от типа задач и бюджета, хостеры предлагают две технологии выделения графической мощности виртуальному серверу пользователя: GPU Passthrough и vGPU.
Технология vGPU (virtual GPU) — архитектурное решение, которое позволяет дробить ресурсы одного физического графического процессора между несколькими независимыми виртуальными машинами. Пользователь может арендовать у провайдера ровно столько мощности vGPU, сколько требует задача, без необходимости переплачивать за работу всего сервера.
Раньше серверы с GPU работали по принципу одна карта — одна виртуальная машина. Это не всегда эффективно: например, если пользователю нужно всего 2 ГБ видеопамяти для работы в AutoCAD, а установлена карта на 24 ГБ, остальной ресурс простаивает и приходится за него переплачивать. Сейчас менеджер виртуализации создаёт виртуальные инстансы графического процессора.
Архитектура vGPU превращает монолитный и дорогой аппаратный ресурс в удобный облачный сервис для бизнеса. В FirstVDS на базе vGPU предлагаются готовые конфигурации VDS с посуточной тарификацией, что позволяет оплачивать ресурсы только в период их фактического использования.
GPU Passthrough — это технология, при которой видеокарта целиком закрепляется за одной виртуальной машиной. Операционная система сервера обращается к устройству напрямую, минуя слой гипервизора. Такой подход исключает потери производительности на виртуализацию и обеспечивает доступ ко всему объёму видеопамяти и ядер. Passthrough применяется в ресурсоёмких проектах: при финальном рендеринге сложных сцен, обучении тяжёлых нейросетей или в масштабных вычислениях, где требуется прямой доступ к аппаратному обеспечению.
Выбор между этими решениями зависит от необходимых ресурсов: vGPU обеспечивает гибкость и позволяет оптимизировать затраты, а GPU Passthrough — предоставляет полный доступ к аппаратной мощности одной или нескольких видеокарт.
Как выбрать сервер с GPU под свою задачу
При подборе ресурсов часто возникают две противоположные проблемы: недостаток мощности или переплата за её избыток. При выборе vGPU нужно соблюдать баланс из трёх характеристик:
- Объём видеопамяти. Зависит от масштаба задачи, которую нужно загрузить в GPU. Если вес нейросети или 3D-сцены не помещается в память целиком, скорость работы упадёт в десятки раз из-за обращения к оперативной памяти (RAM).
- Вычислительная мощность. Количество операций в секунду. От этого зависит, как быстро будет идти обучение или рендеринг кадра.
- Скорость обмена данными. Пропускная способность шины (PCIe), через которую данные поступают из процессора и памяти в GPU.
Если сместить фокус в одну из сторон, оборудование не будет на 100% выполнять поставленную задачу. Разберём требования к оборудованию и оптимальные конфигурации GPU для трёх популярных сценариев: обучения ИИ, инференса моделей в продакшене и работы со сложной графикой.
Обучение нейросетей. Для глубокого обучения и дообучения моделей искусственного интеллекта приоритетный параметр — объём памяти.
Оптимальный выбор — серверы с NVIDIA L40S. С 48 ГБ быстрой памяти GDDR6 и тензорными ядрами четвёртого поколения эти карты позволяют работать с массивными слоями данных. В FirstVDS такие мощности доступны в формате GPU Passthrough, что гарантирует максимальную производительность физической карты для сложных расчётов.
Инференс (работа готовых моделей). Когда модель уже обучена и должна выдавать ответы пользователям (распознавание речи, генерация текста), на первый план выходит минимальная задержка отклика и стоимость одного запроса. Скорость ответа напрямую зависит от пропускной способности памяти — она определяет, насколько быстро графический чип считывает веса модели. Чем выше этот параметр, тем ниже задержка для пользователя и тем дешевле обходится обработка каждого запроса.
Для таких работ подойдут виртуальные серверы с NVIDIA L4. Карта на базе архитектуры Ada Lovelace с 24 ГБ памяти обеспечивает отличную производительность в форматах FP8/INT8 и подходит для продакшн-сред, где важен быстрый отклик и масштабируемость. Этот вариант доступен с посуточной тарификацией, что позволяет платить за сервер только в период активной нагрузки на вашу модель.
3D-графика, рендеринг и CAD. Задачи визуализации требуют высокой частоты графического ядра, наличие RT-ядер и мощного CPU. Такая связка нужна для быстрого рендеринга, трассировки лучей и симуляции физики. При этом само по себе 3D-моделирование много ресурсов видеокарты не потребляет. Всё зависит от сложности сцены: для большинства стандартных проектов вполне хватает от 8 до 16 ГБ. Для комфортной работы с рендерингом в режиме удалённого рабочего стола подойдут vGPU серверы с NVIDIA L4 (16 ГБ).
Для тяжёлых задач: сложной кинематографической графики, инженерного ПО у FirstVDS доступны конфигурации с картами на RTX 4090 (24 ГБ) через Passthrough, чтобы исключить потери производительности на уровне виртуализации.
Офисный и инженерный софт средней нагруженности. Графический процессор здесь нужен для плавной работы специализированных программ, например, AutoCAD, Revit или пакетов обработки графики. Для таких задач не требуется большой объём видеопамяти: под рабочее место со стандартным Full HD-экраном достаточно всего 2 ГБ VRAM. Но если сотрудник работает за 4K-монитором или использует два дисплея, конфигурацию стоит выбрать помощнее — от 4 до 8 ГБ.
Если речь идёт о базовой работе с 3D-моделированием, обработкой несложной графики или работе с базами данных, аренда целой серверной видеокарты будет избыточна и невыгодна. Технология vGPU позволяет вместо аренды отдельных мощных видеокарт для каждого сотрудника арендовать несколько недорогих виртуальных серверов, где одна физическая карта уже разделена хостером на слоты. Каждый сотрудник получит необходимую скорость работы программ, а компания будет платить лишь за полезный объём мощности по гибкому тарифу.
| Задача | На что смотреть в первую очередь | Ориентир по памяти (VRAM) | Рекомендуемое решение |
|---|---|---|---|
| Обучение ИИ | Объём VRAM/Скорость тензорных ядер | От 48 ГБ Для работы со сложными базами данных и LLM | NVIDIA L40S (48 ГБ) |
| Inference ИИ | Цена/Пропускная способность | От 8 до 24 ГБ В зависимости от веса и оптимизации модели | NVIDIA L4 (24 ГБ) |
| 3D / Рендеринг | Объём VRAM/Наличие RT-ядер/Высокая частота чипа/Мощный CPU | От 8 ГБ и более Чтобы тяжёлая геометрия и текстуры помещались в память целиком | NVIDIA L4 (16 ГБ)/RTX 4090(24 ГБ) через Passthrough |
| VDI / Проф. софт | Объём VRAM | От 2 до 8 ГБ На каждого пользователя в зависимости от его задач | NVIDIA L4 / vGPU решения |
Заключение
В споре между CPU и GPU победителей нет — у них разные задачи, масштабы и методы работы. Чтобы компьютер или сервер работали максимально эффективно, важно обеспечить бесшовный тандем:
- CPU остаётся мозгом и дирижёром системы. Он управляет логикой программ, моментально реагирует на системные прерывания, работает с базами данных и координирует распределение задач.
- GPU берёт на себя всю черновую, тяжёлую работу. Он подключается там, где нужно параллельно обработать терабайты однотипных данных — будь то рендеринг сложной 3D-сцены, обработка видеопотока или обучение массивных нейросетей.
Если для ваших задач — будь то обучение нейросетей, рендеринг или работа с Big Data — мощностей текущего железа уже не хватает, а покупка собственных серверов бьёт по бюджету, оптимальным решением станет хостинг с поддержкой GPU Passthrough или vGPU. Это позволит гибко подбирать конфигурацию под конкретный проект и за разумные деньги получить производительную связку из актуальных CPU и флагманских графических процессоров.



