
В современном интернете владельцам сайтов часто приходится сталкиваться с таким явлением как роботы или боты. Это их обобщенное название, которое, правда, не отражает их сути и цели в полной мере. Боты могут выполнять различные задачи, например, мониторить работу сайтов и их доступность, анализировать сайты для сбора информации (seo) или поисковой выдачи (поисковые краулеры) и т. д. И при этом нагружать сервер. Что делать в случаях, когда повышенное внимание ботов приводит к проблемам с доступностью сайтов, рассказываем в статье. Но сперва разберемся с тем, что же это такое боты?
Что такое роботы
Боты (или роботы) — определенный набор программ и алгоритмов, которые посещают сайты в интернете и собирают с них информацию для дальнейшего анализа. Цели использования ботов могут быть разные.
Всех роботов можно разделить на две большие категории в зависимости от задач, которые они выполняют, посещая сайты — «хорошие» и «плохие». Это деление весьма условное, поскольку, например, одним владельцам нужна индексация на Amazon, а другим нет. Что для одного благо, то для другого — проблема.
К хорошим ботам относятся поисковые боты, например, Yandexbot, Googlebot, AmazonBot, Bingbot, Apple Bot и другие, которые собирают информацию для своих поисковых систем. Иногда их называют также web crawler (дословно веб-сканер) или поисковые краулеры. Также хорошими ботами можно назвать, например, ботов проверки авторского права (проверяют веб-контент, который может оказаться плагиатом) или торговых ботов (помогают найти лучшие предложения о продаже товаров онлайн).
К плохим ботам можно отнести кликботы (имитируют клик живого человека), программы-шпионы (собирают данные о людях и компаниях для формирования и продажи подписных баз), зомби-боты (ищут уязвимые места в защите и получают доступ к вычислительной системе) и т. д.
Повышенное внимание со стороны роботов может служить причиной растущей нагрузки на сервер, когда при большом количестве запросов с их стороны возникают проблемы с доступностью всех сайтов, расположенных на сервере.
С одной стороны, владельцам сайтов выгодно внимание ботов к их проектам – сайты будут лучше ранжироваться в поисковой выдаче, а, значит, придет больше посетителей, что положительно повлияет на ресурс в целом. С другой стороны, какой в этом смысл, если дополнительная нагрузка будет тормозить работу сайтов или вовсе делать их недоступными.
Такое внимание со стороны ботов часто похоже на DDoS-атаку большим количеством запросов, но против ботов средства защиты от DDoS-атак (DDG) бессильны — все подобные инструменты безопасности расценивают посещение сайтов «хорошими» ботами легитимным и приносящим их владельцам только выгоду.
Можно, конечно, попытаться заблокировать всех таких «посетителей» с помощью firewall в панели управления сервером, например, ispmanager, или через настройку правил iptables, но в этом случае может пострадать рейтинг SEO (Search Engine Optimization) в поисковой выдаче.
Чтобы снизить нагрузку на сервер и при этом не перекрыть целиком работу хорошим ботам, нужно сделать три простых шага:
- определить, какие конкретно боты заходят на сайт и создают нагрузку;
- грамотно ограничить активность хороших ботов;
- заблокировать работу плохих ботов.
Далее о том, как именно это сделать.
Определение ботов по логам веб-сервера
Поскольку мы уже условно разделили ботов на две категории и дали краткое описание каждого типа, теперь разберёмся, как определить подобных «посетителей» и узнать, кто в большей степени создаёт нагрузку. Первое, что требуется сделать - это проверить, включены ли на вашем сервере логи доступа до вашего сайта (если нет, то включить) и, второе, подробно изучить их.
Например, для стандартной конфигурации хоста в панели ispmanager (если логи доступа были включены при настройке) статистику посещений можно посмотреть с помощью следующей команды из командной строки:
grep "$DATE" /var/www/httpd-logs/*.access.log | awk '{print $1}' | sort | uniq -c | sort -nr | head -n 10Команда выведет вам топ 10 самых активных IP-адресов. Затем необходимо проверить их с помощью онлайн-сервисов для определения ptr-записей, например, https://2whois.ru/?t=ptr или при помощи команды в консоли:
whois IP_ADDRESSДалее по ptr записи вы легко сможете определить хост, с которого был направлен запрос. Затем, используя инструменты поиска, находите описание и решаете, нужен вам такой посетитель или нет. Другими словами, определяете хороший это бот или плохой. Если в поисковой выдаче вы не обнаружили корректного описания, то такого бота можно считать плохим и следует заблокировать его User Agent средствами веб-сервера. Определить User Agent можно по тем же логам доступа, например, используя поиск по IP из командной строки:
grep “IP_BOT” path/to/access.logДанная команда выведет все запросы, по которым можно определить время, страницу сайта, которую посещал хост, и его User Agent. После этого можно ограничить частоту посещений/доступ с помощью файла robot.txt и настроить ограничения инструментами веб-сервера (для полезных ботов и не очень), а также заблокировать доступ для плохих ботов.
Легитимные поисковые боты и файл robot.txt
robots.txt — это простой текстовый файл, который содержит инструкции для роботов поисковых систем — что им можно, а что нельзя. Так, в robots.txt можно ограничить индексирование роботами определенных страниц сайта, что может снизить нагрузку на сайт и ускорить его работу.
Стоит также обратить внимание на то, какие именно вы закрываете страницы для ботов, поскольку неосторожное закрытие станиц может привести к ошибкам индексации. Например, закрытие главной страницы для индексации может негативно сказаться на рейтинге в поисковой выдаче.
Важный момент. robots.txt предназначен, в первую очередь, для хороших ботов, которые используют его инструкции при изучении вашего сайта. И он обязательно должен находиться в корне сайта.
Требования к файлу robots.txt
При создании данного файла необходимо обратить внимание на следующие факторы:
- Файл должен быть в кодировке UTF-8, в текстовом формате .txt. Название в нижнем регистре строго регламентировано в документации поисковых ботов. Если эти условия не будут соблюдены, то робот посчитает, что сайт открыт для его посещения без ограничений.
- Файл должен размещаться в корневом каталоге сайта, например, на сайте
www.example.comон находится по адресуwww.example.com/robots.txt. - Файл должен быть доступен для поисковых роботов. Доступность можно проверить командой:
curl -IL example.com/robots.txtЕсли вы получаете код ответа 200 OK, значит, он доступен. Также можно воспользоваться инструментом по проверке этого файла от Яндекса:
https://webmaster.yandex.ru/tools/robotstxt
Он позволит сразу проверить синтаксис данного файла для бота Yandexbot. Если присутствуют ошибки (404, 403), значит, инструкции в файле недоступны для ботов. Они будут считать, что сайт полностью открыт для индексирования (для многих роботов такое поведение обычно определяется по умолчанию), и вам будет нужно скорректировать конфигурацию вашего сервера для доступа к robots.txt.
- Размер файла не должен превышать 500 КБ.
- Файл работает в рамках только одного домена. Для субдоменов используйте самостоятельные файлы robots.txt. Например, при обращении к поддомену
www.one.example.com, боты не будут учитывать правила из файла robots.txt, если файл расположен только в корневом разделе для доменаwww.example.com. - В файле не должны блокироваться к индексированию неканонические страницы, страницы с метатегом
robots=»noindex»или страницы, с которых настроены редиректы. Иначе поисковые системы эти настройки и сигналы могут не увидеть и не учесть. - В файле нельзя использовать кириллицу. Если всё-таки необходимо использование кириллицы при указании домена или путей сайта, то нужно всё переводить в Punycode. Например, можно воспользоваться бесплатным сервисом для перевода по ссылке https://www.punycoder.com/.
Структура robots.txt
Структура файла, по сути, состоит из секций, в которых указываются разрешенные пути доступа url и для какого бота они предназначены. Секции разделяются пробелами.
Пример простого файла:
User-agent: Yandexbot
User-agent: Googlebot
Disallow: /admin
User-agent: *
Disallow: /Этот файл состоит из двух секций:
- в первой секции — одинаковые правила для Yandexbot и Googlebot (только запрет посещения страницы административной панели на сайте, а всё остальное разрешено — подробнее команды рассмотрим далее).
- во второй секции — для всех остальных ботов (где указано *) запретить доступ к страницам сайта. Здесь действует принцип сначала запретить доступ всем, но разрешить только некоторым.
Директивы в robots.txt
Рассмотрим основные инструкции, которые мы можем указать для ботов:
- User-agent — указывает для кого применяются инструкции в данной секции;
- Disallow — запрещает обход разделов или отдельных страниц сайта. В этой инструкции указываются конкретные пути. Например, путь в примере выше
/admin— это urlhttps://example.com/admin; - Allow — разрешает индексирование разделов или отдельных страниц сайта.
- Sitemap — указывает путь к файлу Sitemap, который размещен на сайте. Данный файл нужен для указания поисковому роботу, какая информация наиболее важна на вашем сайте.
Это далеко не все возможные инструкции понятные роботам, и с полным перечнем вы можете ознакомится на страницах руководств для того бота, который вам необходим.
Примеры содержания файла robots.txt
Если вы хотите полностью закрыть доступ для всех роботов, то содержимое файла можно сделать следующим:
User-agent: *
Disallow: /Таким образом, мы полностью закрываем доступ для всех роботов. Также в документации к некоторым роботам указано, что если бот попадает на страницу сайта через другие сайты, то, даже несмотря на указание полного запрета, робот в этом случае может индексировать страницы. Чтобы этого не происходило, необходимо добавлять директиву noindex в HTML-коде страницы или настраивать HTTP-заголовок страниц определённым образом.
В качестве примера приведем шаблон robots.txt для популярной CMS Bitrix у нас в русскоязычном сегменте:
1С-Битрикс
User-agent: *
Disallow: /cgi-bin
Disallow: /bitrix/
Disallow: *bitrix_*=
Disallow: /local/
Disallow: /*index.php$
Disallow: auth
Disallow: /personal/
Disallow: *register=
Disallow: *forgot_password=
Disallow: *change_password=
Disallow: *login=
Disallow: *logout=
Disallow: */search/
Disallow: *action=
Disallow: *print=
Disallow: *?new=Y
Disallow: *?edit=
Disallow: *?preview=
Disallow: *backurl
Disallow: *captcha
Disallow: *?FILTER*=
Disallow: *?ei=
Disallow: *?p=
Disallow: *?q=
Disallow: *?tags=
Disallow: *B_ORDER=
Disallow: *BRAND=
Disallow: *CLEAR_CACHE=
Disallow: *ELEMENT_ID=
Disallow: *price_from=
Disallow: *PROPERTY
Disallow: *S_LAST=
Disallow: *SECTION
Disallow: *SHOW
Disallow: *SORT=
Disallow: *SPHRASE_ID=
Disallow: *TYPE=
Allow: */upload/
Allow: /bitrix/*.js
Allow: /bitrix/*.css
Allow: /*.js
Allow: /*.css
Allow: /*.png
Allow: /*.gif
Allow: /*.jpeg
Allow: /*.jpg
Allow: /*.svg
# Необходимый указать путь к XML-карте сайта
Sitemap: https://site.ru/sitemap.xmlЕсли после корректной установки файла для поисковых краулеров или других ботов, роботы продолжают создавать нагрузку на сервер, можно прибегнуть также к таким способам, как :
- ограничить частоту обращений через инструменты, которые предоставляют сами разработчики, скажем, в Вебмастере от Yandex, например, для поисковых краулеров таких, как Yandexbot,
- также можно ограничить частоту обращений полезных ботов с помощью инструментов веб-сервера по User Agent (об этом далее).
Пока мы с вами учитывали лишь порядочных (хороших) роботов, которые следуют правилам в файле robots.txt и применяют их. При этом плохие боты даже не будут искать файл robots.txt, не то что следовать указанным в нём правилам. Чтобы заблокировать ботов, которые вам не нужны, вы можете также использовать средства веб-сервера, о чем мы расскажем дальше.
Для плохих роботов мы обязательно рекомендуем это сделать.
Блокировка или ограничение ботов средствами веб-сервера
В зависимости от конфигурации вашего сервера ограничение на количество запросов от ботов и блокировку по User Agent можно сделать на веб-сервере Nginx или Apache. Со списком известных «плохих» ботов по IP или User Agent можете ознакомится вот тут.
Если у вас есть доступ к конфигурации Nginx, то лучше использовать именно его. Это также является хорошей практикой. Дополнительные правила в .htaccess для Apache могут навредить скорости ответа сервера. Это связано с тем, что веб-сервер будет вынужден при каждом обращении к нему проверять все правила для User Agent, и, если их будет много, проверка со стороны веб-сервера будет вызывать дополнительную нагрузку на ваш сервер.
Также стоит отметить, что блокировка по User Agent не является гарантией защиты от злоумышленников, т. к. User Agent в заголовке мы можем указать любой. Поэтому злоумышленники могут могут маскировать плохих ботов под хорошие, изучая ваш сайт для своих целей. Об этом поговорим ниже — после проведения настройки веб-сервера, на этапе проверки.
Nginx
В случае веб-сервера nginx необходимо менять общую конфигурацию в секции http или server. И поскольку черный список пользовательских агентов может вырасти довольно большим, помещать их все в общий раздел сервера nginx — не лучшая идея. Мы рекомендуем создать отдельный файл со списком всех нежелательных пользовательских агентов.
Если вы не хотите полностью блокировать доступ до вашего веб-сервера, а лишь ограничить частоту обращения к вашему сайту, то нужно создать файл /etc/nginx/conf.d/useragent.rules.conf и и указать следующее содержание:
map $http_user_agent $badagent {
default 0;
~*bandit 1;
~virus 1;
~BadSpider 1;
}
map $badagent $limit_bot {
0 "";
1 $binary_remote_addr;
}
limit_req_zone $limit_bot zone=bots:10m rate=1r/m;
limit_req_zone $binary_remote_addr zone=one:10m rate=10r/s;
limit_req zone=bots burst=2 nodelay;
limit_req zone=one burst=15 nodelay;
limit_req_status 429;Таким образом при большой частоте обращений для всех запросов будет отдаваться ответ 429 “Too Many Requests”, что снизит нагрузку на ваш сервер.
Оператор ~* будет соответствовать ключевому слову без учета регистра, а оператор ~ будет соответствовать ключевому слову, используя регулярное выражение с учетом регистра. Строка, в которой указано значение по умолчанию 0, означает, что будет разрешен любой другой пользовательский агент, не указанный в файле.
Затем откройте файл конфигурации nginx вашего веб-сервера, который содержит раздел http , и добавьте следующую строку где-нибудь внутри этого раздела:
http {
.....
include /etc/nginx/conf.d/useragent.rules.conf
}Обратите внимание, что этот оператор включения должен стоять перед разделом сервера (именно поэтому мы добавляем его внутри раздела http). Поскольку мы указали данный файл в каталоге /etc/nginx/conf.d, у вас в конфигурации уже может быть указание на включение всех файлов из каталога conf.d, например:
http {
.....
include /etc/nginx/conf.d/*.conf;
.....
}В этом случае не нужно ничего указывать в основной конфигурации. Если указанная выше строка отсутствует, то её следует добавить.
Далее необходимо проверить конфигурацию:
nginx -tЕсли вы увидели следующие строки:
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successfulЗначит ошибок в синтаксисе нет, и можно перезагружать конфигурацию nginx:
nginx -s reloadили
systemctl reload nginxЕсли вы решите полностью заблокировать доступ к вашему сайту определённым ботам, то можно отредактировать конфиг и указать, кого именно нужно заблокировать.
Например, создадим /etc/nginx/conf.d/useragent.rules.conf и определим карту всех заблокированных пользовательских агентов в следующем формате:
vi /etc/nginx/conf.d/useragent.rules.conf
map $http_user_agent $badagent {
default 0;
~*bandit 1;
~virus 1;
~BadSpider 1;
}Теперь откройте конфигурацию nginx, в которой определен раздел вашего сервера, и добавьте следующий оператор if :
server {
....
if ($badagent) {
return 403;
}
....
}Теперь любой пользовательский агент с ключевым словом, указанным в /etc/nginx/useragent.rules.conf, будет автоматически заблокирован nginx.
После изменения конфигурации нужно также перезагрузить nginx, как было указано выше.
Apache и .htaccess
Чтобы заблокировать пользовательские агенты в Apache, вы можете использовать модуль mod_rewrite. Для начала необходимо убедиться в том, что модуль включен:
a2enmod rewriteПредполагая, что .htaccess уже есть на вашем сервере (он есть на большинстве серверов, на которых работает Apache, и находится в корневом каталоге сайта), добавьте следующие строки в файл .htaccess, либо в соответствующий файл конфигурации:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} badagent [NC]
RewriteRule .* - [F,L]
<IfModule mod_rewrite.c>Если у вас расположено несколько сайтов на севере и вы хотите заблокировать ботов на определенном, то вы можете поместить их в соответствующий раздел VirtualHost.
В следующем примере будут блокироваться любые запросы, содержащие строку пользовательского агента badcrawler, badbot или badagent.
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} badcrawler [NC,OR]
RewriteCond %{HTTP_USER_AGENT} badbot [NC,OR]
RewriteCond %{HTTP_USER_AGENT} badagent [NC]
RewriteRule .* - [F,L]
<IfModule mod_rewrite.c>Если вы хотите заблокировать сразу несколько пользовательских агентов в .htaccess, то вы можете объединить их в одну строку следующим образом:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} ^(badcrawler|badbot|badagent) [NC]
RewriteRule .* - [F,L]
</IfModule>Альтернативно вы можете использовать блок SetEnvIfNoCase, который устанавливает переменную среды, если описанное условие выполнено. Это может быть полезно, если по какой-то причине mod_rewrite недоступен.
<IfModule mod_setenvif.c>
SetEnvIfNoCase User-Agent (badcrawler|badbot|badagent) bad_user_agents
Order Allow,Deny
Allow from all
Deny from env=bad_user_agents
</IfModule>Если вы изменяли файл .htaccess, то можно сразу переходить к проверке результата. Если вы изменяли конфигурационные файлы веб-сервера, то необходимо проверить конфигурацию и перезапустить его:
apachectl -t
systemctl restart apache2 # для Ubuntu или Debian
systemctl restart httpd # для CentOsСтоит также отметить, что возможность блокировки сайта в файле .htaccess присутствует, только если ваш веб-сервер работает на связке Nginx + Apache. В противном случае, если ваш сайт работает на Nginx + PHP-FPM, то инструкции не будут обрабатываться в .htaccess.
Проверка wget и curl
Возьмите любого бота, которого вы уже заблокировали в конфигурации ранее, и проверьте с помощью утилиты curl доступность сайта для конкретного User Agent:
curl -IL --user-agent "YOUR_BAD_BOT" http://your_site.ru/Например, как мы уже настраивали в конфигурации nginx, попробуем сделать запрос с пользовательским агентом virus и Virus (в конфигурации мы указали его как регистрозависимый):
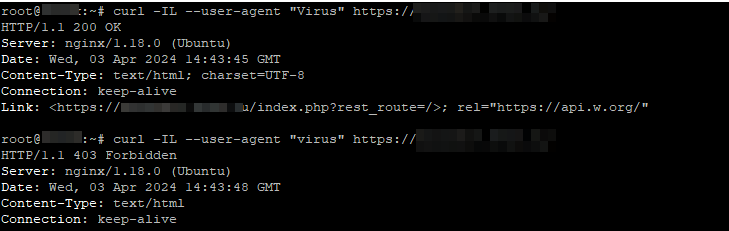
При запросе с заглавной буквой мы получили ответ от сервера 200, и это означает, что бот с данным пользовательским агентом может получать информацию с нашего сайта. В случае с запросом со строчной буквы получили ответ 403, т. е. доступ запрещён.
Другая ситуация, если мы сделаем запрос от бота с пользовательским агентом bandit:
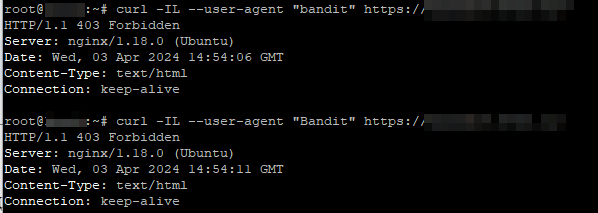
В двух случаях мы получили 403 ошибку, а значит, доступ запрещен для данного агента (бота) .
Также проверить доступ до сайта можно, используя утилиту wget. Принципиальных отличий от команды curl нет. Команда для проверки заблокированных user-agent будет выглядеть так:
#Если на вашем домене нет сертификата
wget --user-agent "YOUR_BAD_BOT" --no-check-certificate https://sitename.ru
#Если сертификат уже есть
wget --user-agent "YOUR_BAD_BOT" https://sitename.ruПроверим блокировку ботов, которых мы блокировали в примере с .htaccess.

Как мы видим по выводу команды, доступ запрещен. Но попробуем пропустить одну из букв (или несколько) при указании пользовательского агента:
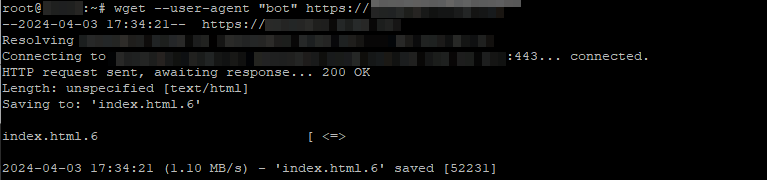
Как можно увидеть из ответа сервера, бот успешно получил доступ к сайту, поэтому блокировка по пользовательским агентам поможет лишь в том случае, если поисковые краулеры заблокированы в robot.txt, и попадают на ваш сайт с других ресурсов. Отследить подобное поведение можно, внимательно изучив логи доступа на вашем сервере.
И тем более методы блокировки по user agent не помогут защититься от злоумышленников при атаке DDoS, поскольку блокировка трафика по пользовательским агентам не будет отличаться от большого наплыва посетителей на вашем сайте, как вы могли убедится на примерах с запросами через curl или wget. Для этого существуют другие инструменты, например, защита от DDoS-атак.
Заключение
В этой статье мы рассмотрели, что такое боты, как определить, какие боты посещают сайт, как правильно создать и проверить файл robots.txt. Также познакомились с возможностями веб-серверов для ограничения или блокировки роботов по User Agent и разобрались, как проверить полученную конфигурацию на практике с помощью запросов к вашему сайту. Надеемся, что это поможет вам правильно выстраивать работу с ботами в сети и избегать лишней нагрузки на сайт и сервер.


