Что будет, если однажды компьютер со всеми вашими документами или сервер, обслуживающий сайт, над которым вы так долго трудились, вдруг перестанет существовать? Просто задайте себе этот вопрос. А если это произойдёт в отчетный период, когда вам нужно срочно сделать выгрузку данных в 1С, а клиенты требуют актов сверки, скидок и бонусов за совершённые покупки? А ведь в истории такое уже случалось. Даже самый современный и защищённый дата-центр подвержен стихийным бедствиям и катаклизмам. Но обычно потеря данных происходит по более прозаическим причинам.
Человеческий фактор. Да, люди ошибаются, и никто от этого не застрахован.
Ошибки в программах. Часто причиной «падения» сайта является неудачное обновление базы данных, файлов или скриптов.
Сбой оборудования. Это случается реже, но всё же возможно. Например, если ваш сайт работает на выделенном сервере, вам нужно следить за состоянием жёстких дисков, хранящих данные, и своевременно производить их замену.
Хакерские атаки. Злоумышленники могут задаться целью исказить ваши данные. Увы, в современном мире случается и такое.
В любом случае, страховкой от потери критически важных для вас и вашего бизнеса данных будет резервное копирование. Сегодня мы постараемся дать ответы на некоторые вопросы по сохранению информации и системных настроек, применимые как к серверу, так и к локальной установке Linux.
Что копировать?
Давайте будем считать, что ваш сайт или персональный компьютер работает на одном из deb- или rpm-based дистрибутивов Linux (Debian, CentOS и так далее). Тогда можно рекомендовать сохранить вот что:
1. Настройки системы. В Linux все основные настройки хранятся в директории /etc. Как правило, эта папка занимает относительно небольшой объём и её можно поместить в архив полностью, например так:
sudo tar -czf etc.tar.gz /etc/Эта консольная команда создаст сжатый архив etc.tar.gz в текущей директории. Конечно, вы можете сохранить образ всей файловой системы, например, командой dump, но обычно в этом нет смысла — Linux достаточно просто устанавливается штатными средствами, поэтому файлы программ, за исключением ваших собственных, не представляют особой ценности.
2. Данные пользователей. По умолчанию все ваши документы и персональные настройки находятся в папке /home/имя_пользователя/ (сокращённо ~/). В основном, директории /home/ важны для персональных компьютеров. Если сохранить эту папку, то даже после миграции на другой дистрибутив вы сможете продолжить работу, как ни в чём не бывало. Если вы решите сохранить резервную копию этой папки целиком, не забудьте исключить из архива директории .cache/, содержащие временные файлы, — это сэкономит вам немного места.
3. Базы данных (БД). Например, если ваш сайт хранит данные в реляционной базе данных MySQL или PostgreSQL, то выгрузка резервной копии выполняется так:
sudo mysqldump опции имя_базы_данных > имя_файла.sqlдля MySQL и
sudo pg_dump опции имя_базы_данных > имя_файла.sqlдля PostgreSQL.
Эти команды создадут так называемую «логическую» резервную копию указанной базы данных. Вы также можете создать копию сразу всех баз данных или, наоборот, только нужных вам таблиц. Полный список опций можно найти в официальной документации по MySQL и PostgreSQL.
Конечно, вы можете просто создать «физический» архив файлов, содержащих вашу базу данных, упомянутой выше командой tar, но это настоятельно не рекомендуется. Во-первых, создание такого архива может совпасть со временем записи в базу или проведения каких-либо транзакций, и данные в архиве окажутся повреждёнными. Во-вторых, за время хранения архива версия базы данных может обновиться, и старый формат данных просто не будет работать.
4. Файлы посетителей и другие данные сайта. Не всё можно поместить в базу данных. Например, «аватарки» пользователей или фотографии товаров часто хранятся в виде файлов на диске. В таком случае важно также поместить директории с этими файлами в резервную копию.
Разумеется, при сохранении важных данных нужно не забыть ограничить права доступа к архиву.
Куда копировать?
Мы уже знаем, как сохранить архивы на тот же жёсткий диск или массив дисков — RAID (Redundant Array of Independent Disks), где хранится рабочая копия сайта. Но в случае недоступности сервера или выхода из строя дисков данные всё же окажутся потерянными.
Кроме того, архивы могут занимать значительный объём дискового пространства, поэтому лучше всего выполнять резервное копирование на удалённый сервер или в облако, желательно находящееся в другом географическом местоположении.
Помните, что место на диске — один из важнейших факторов при выборе стратегии резервного копирования. Чрезмерное заполнение дисковых накопителей может привести к их деградации и остановке рабочих процессов.
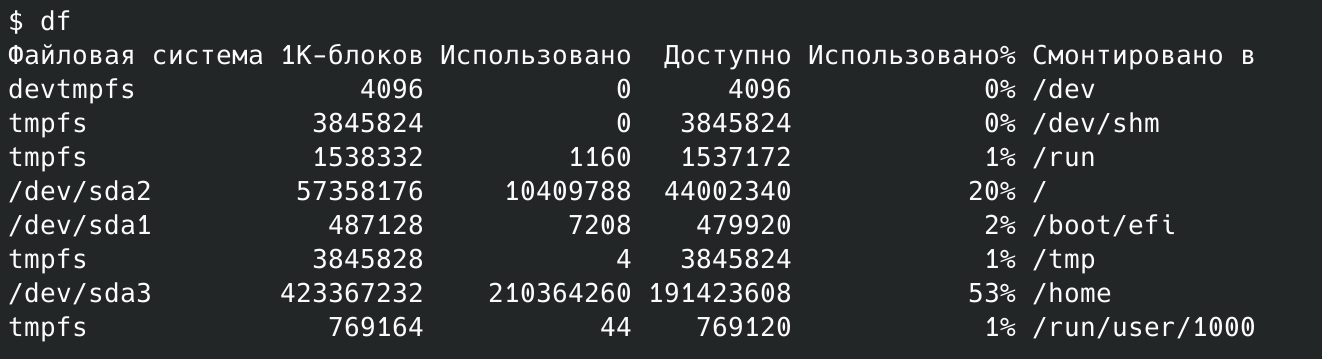
Оценить использование дисков можно, например, с помощью команды df (disk free):
Как копировать?
Для передачи и синхронизации данных Linux предлагает прекрасный набор инструментов и средств автоматизации. Вот некоторые из них:
1. Rsync (Remote Sync) — это мощная универсальная консольная утилита, позволяющая очень быстро и эффективно синхронизировать ваши данные между удалёнными компьютерами. Высокая скорость и низкий межсетевой трафик достигаются за счёт передачи только изменённых блоков между двумя наборами файлов и использования сжатия, а безопасность обеспечивается благодаря использованию защищённых сетевых протоколов.
Базовый синтаксис команды при выгрузке данных на удалённый компьютер может выглядеть так:
sudo rsync -a /локальная_директория логин@ip_адрес:/удалённая_директорияКонечно, для идентификации пользователя на удалённом компьютере лучше использовать авторизацию по ключу.
Полный список опций доступен по команде man rsync или на официальном сайте.
В качестве простого примера давайте поместим команды резервного копирования в shell-скрипт backup.sh.
sudo nano /путь_к_файлу/backup.shпримерно такого содержания:
#!/bin/sh
mysqldump опции имя_базы_данных | ssh логин@ip_адрес:/удалённая_директория 'cat > имя_базы_данных.sql'
rsync -a /var/www/html логин@ip_адрес:/удалённая_директорияи дадим файлу права на выполнение:
sudo chmod 700 /путь_к_файлу/backup.shЭтот скрипт сохранит дамп базы данных и файлы сайта из директории /var/www/html/ на удалённый сервер, используя безопасный протокол передачи данных SSH.
Подробнее о возможностях утилиты Rsync можно почитать в отдельной статье.
2. Rclone (rsync for cloud storage, rsync для облаков) — другая полезная утилита для резервного копирования в облачные хранилища. Работает с Google Drive, Yandex Disk, Mail.ru Cloud, Dropbox, Microsoft OneDrive, Amazon S3, Cloudflare R2, DigitalOcean Spaces и многими другими.
Инструкцию по установке и настройке можно найти на официальном сайте.
Команда для синхронизации данных между локальной директорией и облачным хранилищем выглядит так:
rclone sync /локальная_директория имя_хранилища:имя_контейнераПри необходимости эту команду также можно добавить в наш скрипт backup.sh.
Как всегда, вы можете ознакомиться со всеми параметрами утилиты с помощью команды man:
3. Распределённые системы контроля версий (Version Control System, VCS), например Git. Да, вы не ослышались — Git, хотя и не является средством резервного копирования, весьма успешно способствует сохранности рабочих данных. Дело в том, что в силу своей децентрализации в случае выхода из строя одного из компьютеров вы всегда сможете выполнить команды git push или git clone после восстановления системы, тем самым потеряв лишь незначительную часть данных после последнего коммита.
Если вы ещё не используете Git в работе, возможно, сейчас пришло время задуматься об этом.
4. Репликация данных. Применяется в основном на высоконагруженных системах для немедленного согласования данных прямо во время их записи. Описание механизмов репликации выходит за рамки этого обзора, но всё-таки полезно знать, что такая возможность существует.
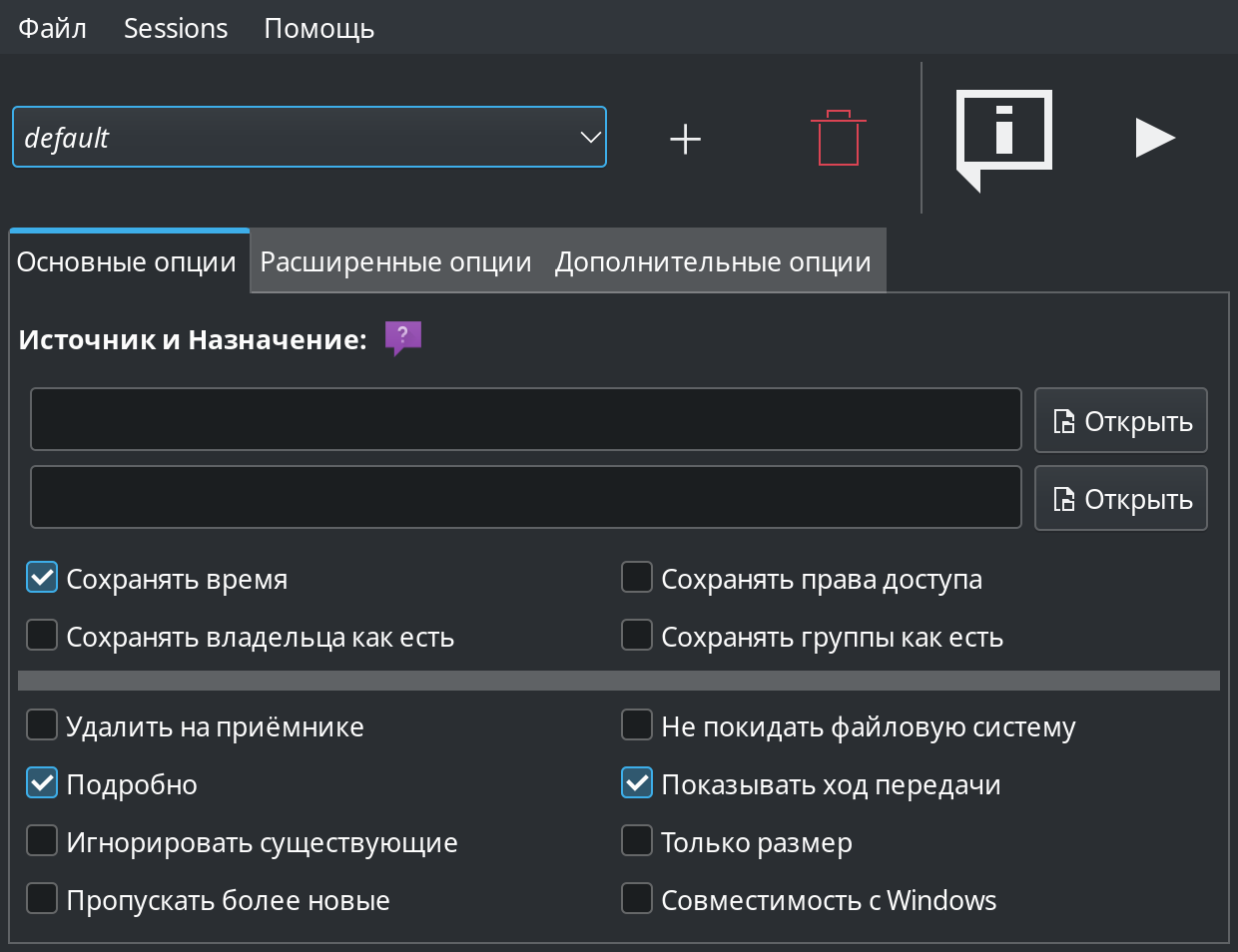
5. Приложения с графическими интерфейсами (GUI). В качестве примера можно привести grsync:
и backintime-qt:
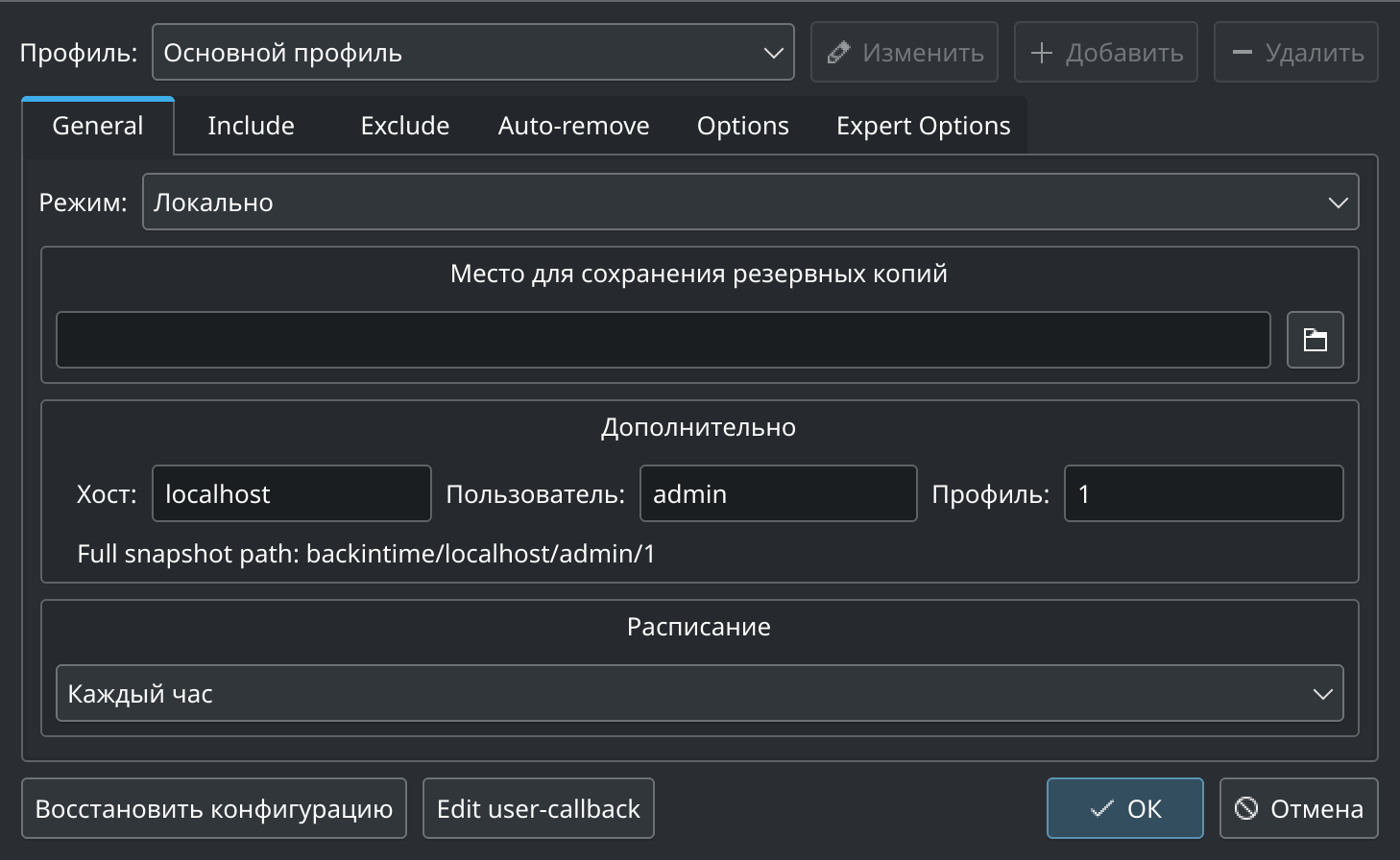
Первый использует библиотеку GTK, а второй, как следует из названия, — QT. Оба приложения входят в состав основных репозиториев Debian и CentOS. Поскольку приложения этого типа используют графическую среду, они подходят только для локальной установки.
Настоятельно рекомендуем устанавливать на рабочий сервер только минимально необходимый набор утилит, по возможности не использовать веб-интерфейсы для администрирования системы (такие как phpMyAdmin) и без крайней необходимости не открывать порты для доступа к службам (например 3306 для MySQL). Дело в том, что автоматические сетевые сканеры хакеров очень быстро обнаружат любой открытый порт на «белом» IP-адресе и немедленно предпримут попытки взлома. Увы, современный цифровой мир не идеален.
И, конечно, при копировании информации по сети важно использовать защищенный протокол передачи данных.
Когда копировать?
Это зависит от количества транзакций, выполняемых вашим сервером в единицу времени и от критичности потери сохраняемых данных. Решать вам. Но нужно помнить, что максимальное время недоступности данных складывается из интервала резервного копирования (Recovery Point Objective) и времени восстановления данных (Recovery Time Objective).
В любом случае, лучше настроить автоматическую выгрузку данных по расписанию. В качестве примера давайте возьмём скрипт backup.sh из предыдущего раздела и настроим для него автоматический запуск.
Самый простой вариант запуска shell-cкриптов по расписанию — использование планировщика cron:
sudo crontab -eЭта команда откроет для редактирования список заданий для пользователя root. Добавьте в этот список строку
0 1 * * * /usr/bin/sh /путь_к_файлу/backup.shТеперь cron будет автоматически выполнять скрипт backup.sh раз в сутки в 01:00.
Но cron не единственный планировщик в современном Linux. Таймеры (timer) systemd также выполняют нужные действия в системе по расписанию, но имеют ряд преимуществ. Например, таймеры могут срабатывать по истечении некоторого времени после указанного события, даже если это событие — завершение предыдущего таймера. Кроме того, таймеры легче отлаживать, потому что информация о их работе всегда доступна в системе благодаря стандартным командам systemctl и journalctl. Можно сказать, что таймеры — более современная, гибкая и дружественная замена cron. Советуем попробовать запустить наш bacup.sh с помощью таймера, это действительно удобно.
Исчерпывающую документацию по созданию и настройке таймеров можно найти, например, в ArchWiki.
Обратите внимание, что скрипт backup.sh в нашем примере не выгружает настройки системы. Дело в том, что в реальных условиях файлы в /etc/ изменяются редко, а интенсивность записи в БД, наоборот, может быть высокой. В таком случае рассмотрите возможность разделить скрипты резервного копирования по интервалу выполнения и сохранять наиболее часто изменяемые таблицы БД отдельно. Это поможет снизить нагрузку на процессор и сетевой трафик во время выгрузки.
Если объём вашей базы данных вырос настолько, что резервное копирование вызывает слишком большую нагрузку на процессор и нежелательный сетевой трафик, а выполнять архивирование нужно достаточно часто, можно рассмотреть возможность создания инкрементальных или дифференциальных копий, например с помощью утилиты Percona XtraBackup для MySQL или pgBackRest для PostgreSQL.
Сколько хранить?
Это также зависит от интенсивности записи данных и минимального интервала резервного копирования. Например, если вы настроите выгрузку данных раз в сутки, логично будет хранить по одной копии за последние 7 дней и по одной — за каждую неделю последнего месяца. Итого получаем 7 + 4 = 11 копий.
Так как архивы могут занимать значительный объём дискового пространства, для полноценного резервного копирования может потребоваться дополнительное место.
Устаревшие данные следует удалять либо по расписанию, либо сразу после сохранения очередной копии, чтобы освободить место на диске. В примере выше мы использовали shell-скрипт backup.sh, и вы можете поручить ему и эту работу. Этот процесс называется «ротацией». В интернете найдётся множество примеров подобных скриптов. Если написание сценария на shell вызывает сложности, можно использовать стандартные механизмы ротации, например logrotate, или программы на других языках.
Восстановление данных
Если вам удалось добиться самого главного — вы получили, что восстанавливать, то остальное точно не вызовет трудностей. Просто используйте операции, обратные тем, что применяли при архивировании, например
sudo tar -xzf etc.tar.gzпри распаковке файлов в директорию /etc,
sudo mysql опции имя_базы_данных < имя_файла.sqlдля восстановления базы данных MySQL и
sudo psql опции имя_базы_данных < имя_файла.sqlдля PostgreSQL.
При восстановлении данных с удалённого сервера рекомендуется использовать безопасный протокол SSH с авторизацией по ключу так же, как мы делали при выгрузке архивов.
Проверка данных
Инженеры, связанные с информационными технологиями, в шутку разделяют пользователей на тех, кто ещё не делает копии и тех, кто уже делает, а администраторов — на тех, кто сохраняет резервные копии, и тех, кто сохраняет и проверяет резервные копии. И проверка актуальности данных действительно очень важна. Дело в том, что в процессе работы вы можете, например, перенести важные файлы в другую директорию, но забыть поменять нужную настройку в скрипте. Тогда резервные копии будут продолжать создаваться с неполным или пустым набором данных, а у вас может возникнуть иллюзия, что ваши бизнес-процессы защищены. А это не так.
В качестве страховки от подобных ситуаций рекомендуем, например, автоматически отправлять администраторам письма с отчётом о количестве файлов в резервных копиях и суммарном объёме архива. Эти цифры обычно имеют тенденцию расти, и если вы вдруг заметите снижение показателей, это будет сигналом тревоги. Ну и, конечно, стоит периодически проверять возможность восстановления архивов, например в отдельном контейнере.
К сожалению, оценить целостность данных цифрами не всегда возможно. Например, если в базу данных попадут несогласованные записи о неверной транзакции, скрипт резервного копирования постепенно заменит все копии этими ошибочными данными. Универсального средства от таких ошибок не существует. Поможет только ваша внимательность и часто, как ни удивительно, реакция пользователей.
Заключение
Надеемся, нам удалось обозначить основные моменты, на которые следует обратить внимание при настройке резервного копирования. Мы понимаем, что, скорее всего, ответили не на все ваши вопросы. Но безопасность вашей информации только в ваших руках, а бизнес-процессы часто уникальны. Поэтом все решения принимать именно вам, а мы лишь ещё раз напомнили позаботиться обо всём заранее.
Возможно, вам будет интересно



