vLLM — это сервер инференса для больших языковых моделей с OpenAI-совместимым API. С его помощью можно поднять локальный API-сервер и обращаться к модели почти так же, как к OpenAI API: отправлять запросы на /v1/chat/completions, подключать свои приложения, агентов или интерфейсы.
В статье пойдём от простого к сложному. Сначала поставим vLLM и запустим небольшую базовую модель, чтобы проверить окружение без борьбы за каждый гигабайт VRAM. После этого перейдём к тяжёлой модели Qwen/Qwen3.5-35B-A3B-GPTQ-Int4 и уже на её примере разберём параметры запуска.
Установить vLLM можно двумя способами:
- локально через uv, если вы хотите сами управлять Python-окружением;
- через Docker, если удобнее держать сервер в контейнере.
Оба варианта дают одинаковый результат: локальный OpenAI-совместимый API на выбранном порту.
Требования и ограничения
Для базового теста лёгкой модели достаточно будет сервера со следующими характеристиками:
- NVIDIA GPU с 8–12 GB VRAM;
- 16–32 GB RAM;
- 20–50 GB свободного места на диске;
- Linux-сервер, желательно Ubuntu 22.04/24.04;
- установленный NVIDIA Driver;
- CUDA-совместимое окружение.
А для примера с Qwen/Qwen3.5-35B-A3B-GPTQ-Int4 минимум нужно иметь:
- NVIDIA GPU с 24GB VRAM;
- 64-128 GB RAM;
- 100–200 GB свободного места на диске.
Вариант 1. Локальная установка через uv
Этот способ подойдёт, если вы хотите поставить vLLM напрямую в систему и запускать сервер из виртуального окружения.
Устанавливаем uv
Сначала установим uv:
curl -LsSf https://astral.sh/uv/install.sh | shПосле установки перезапустите shell или выполните:
source ~/.bashrcСоздаём рабочую директорию
mkdir -p /opt/vllm
cd /opt/vllmСоздаём виртуальное окружение
Для такого сценария удобно использовать Python 3.12:
uv venv --python 3.12 --seed --managed-python
source .venv/bin/activate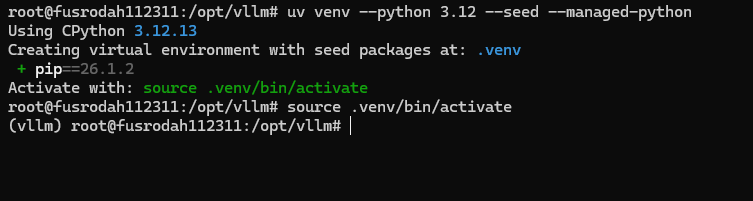
Устанавливаем vLLM
uv pip install vllm --torch-backend=autoНа этом локальная установка завершена. Дальше можно запускать тестовую модель.
Вариант 2. Установка и запуск через Docker
Docker удобен, если вы не хотите ставить vLLM в систему. Контейнер проще перенести на другую машину, обновить или удалить вместе со всеми зависимостями.
Что понадобится
Перед запуском проверьте, что уже установлены:
- Docker;
- драйвер NVIDIA;
- NVIDIA Container Toolkit, чтобы контейнер видел GPU.
Как установить Docker, можно посмотреть в статье «Как установить Docker на Ubuntu».
Если модель на Hugging Face требует авторизации, заранее подготовьте токен HF_TOKEN из личного кабинета. Для небольшой тестовой модели из примера ниже он обычно не нужен, но для закрытых или gated-моделей без него загрузка не начнётся.
Подготавливаем кеш Hugging Face
Чтобы веса модели не скачивались заново при каждом запуске контейнера, создадим локальный кеш:
mkdir -p ~/.cache/huggingfaceПервый запуск: базовая модель
Начнём с небольшой модели Qwen/Qwen2.5-0.5B-Instruct. Она нужна не для качества ответов, а для проверки, что vLLM установлен, видит GPU и отдаёт OpenAI-совместимый API.
Такой тест лучше делать до запуска тяжёлой модели. Если что-то не работает, вы быстрее поймёте, где проблема: в окружении, Docker, драйвере, портах или токене Hugging Face.
Локальный запуск через uv
Если вы ставили vLLM локально, запустите модель так:
vllm serve "Qwen/Qwen2.5-0.5B-Instruct" \
--host 127.0.0.1 \
--port 8000 \
--served-model-name qwen-baseЗдесь мы почти не добавляем параметров. Для базовой проверки достаточно указать модель, адрес, порт и короткое имя, по которому будем обращаться к серверу.
Запуск через Docker
Если вы выбрали Docker, запустите контейнер с той же базовой моделью:
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model Qwen/Qwen2.5-0.5B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--served-model-name qwen-baseВ Docker-версии --host должен быть 0.0.0.0, иначе сервер будет слушать только внутренний localhost контейнера и с хоста до него можно не достучаться.
Проверяем базовую модель
Когда сервер запустится и начнёт слушать порт 8000, отправьте тестовый запрос:
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen-base",
"messages": [
{"role": "user", "content": "Ответь одним словом: работает?"}
],
"temperature": 0
}'Если всё настроено правильно, vLLM вернёт JSON в OpenAI-совместимом формате. Внутри ответа получите сообщение от модели. Для такого запроса она обычно отвечает «да».
После проверки базовую модель можно остановить: нажмите Ctrl+C в терминале с локальным запуском или завершите работу Docker-контейнера Docker-контейнер.
Переходим к тяжёлой модели
Теперь можно запускать тяжёлую модель Qwen/Qwen3.5-35B-A3B-GPTQ-Int4. Это уже не просто проверка установки: такая модель сильнее нагружает видеокарту, активнее использует память и требует более аккуратных параметров.
Для видеокарт уровня RTX 5090 квантованная Int4-версия выглядит практичнее полной модели: она всё ещё крупная, но расход VRAM ниже. При этом запас по памяти всё равно лучше оставить, особенно если вы хотите длинный контекст.
Локальный запуск
vllm serve "Qwen/Qwen3.5-35B-A3B-GPTQ-Int4" \
--host 127.0.0.1 \
--port 8000 \
--served-model-name qwen3.5-openclaw \
--quantization moe_wna16 \
--dtype bfloat16 \
--kv-cache-dtype fp8 \
--max-model-len 16384 \
--max-num-seqs 1 \
--gpu-memory-utilization 0.90 \
--language-model-only \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--enforce-eager
Запуск через Docker
В Docker команда выглядит почти так же, только параметры vLLM передаются после имени образа:
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HF_TOKEN=ВАШ_HF_TOKEN" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model Qwen/Qwen3.5-35B-A3B-GPTQ-Int4 \
--host 0.0.0.0 \
--port 8000 \
--served-model-name qwen3.5-openclaw \
--quantization moe_wna16 \
--dtype bfloat16 \
--kv-cache-dtype fp8 \
--max-model-len 16384 \
--max-num-seqs 1 \
--gpu-memory-utilization 0.90 \
--language-model-only \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--enforce-eagerВ этой команде Docker-флаги и параметры vLLM относятся к разным частям запуска. Всё до vllm/vllm-openai:latest настраивает контейнер: GPU, кеш, переменные окружения, порт и shared memory. Всё после имени образа передаётся самому vLLM.
Проверяем тяжёлую модель
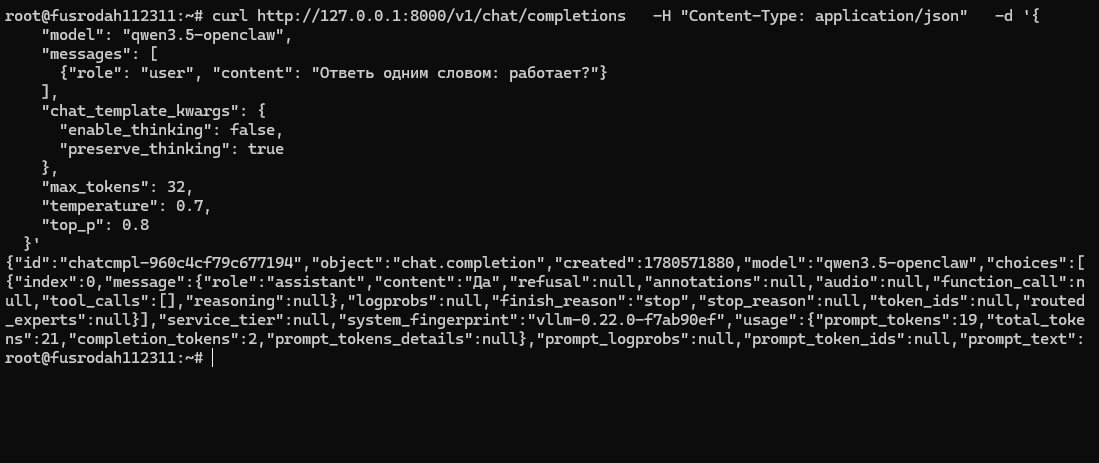
Для проверки используем уже другое имя модели — то, которое указали в --served-model-name:
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.5-openclaw",
"messages": [
{"role": "user", "content": "Ответь одним словом: работает?"}
],
"temperature": 0
}'Если сервер поднялся корректно, модель вернёт ответ в OpenAI-совместимом формате.
Разбор параметров
В базовом примере мы почти ничего не настраивали. Для тяжёлой модели параметры уже важны: они влияют на расход VRAM, длину контекста, совместимость и то, как клиенты будут обращаться к модели.
vllm serve "Qwen/Qwen3.5-35B-A3B-GPTQ-Int4" запускает vLLM и загружает модель из Hugging Face. В Docker-версии ту же роль выполняет параметр --model Qwen/Qwen3.5-35B-A3B-GPTQ-Int4.
--host 127.0.0.1 ограничивает доступ к серверу локальной машиной. Это безопасный вариант для запуска без внешнего доступа. В контейнере обычно ставят --host 0.0.0.0, чтобы сервер был доступен через проброшенный порт.
--port 8000 задаёт порт API. Если 8000 уже занят, выберите другой порт и используйте его же в curl-запросах.
--served-model-name qwen3.5-openclaw задаёт имя модели для API-клиентов. Это алиас: вместо длинного имени Hugging Face в запросах можно писать qwen3.5-openclaw.
--quantization moe_wna16 указывает режим квантования. Для MoE-модели это помогает vLLM правильно загрузить веса и использовать подходящий путь выполнения.
--dtype bfloat16 задаёт основной тип вычислений. На современных NVIDIA GPU bfloat16 часто даёт хороший баланс между скоростью, стабильностью и расходом памяти.
--kv-cache-dtype fp8 хранит KV-cache в fp8. KV-cache растёт вместе с длиной контекста, поэтому fp8 помогает экономить VRAM на длинных запросах.
--max-model-len 16384 задаёт максимальную длину контекста в токенах. Чем больше значение, тем больше памяти может потребоваться под KV-cache.
--max-num-seqs 1 ограничивает число одновременно обрабатываемых последовательностей. Для одиночного локального запуска это простой способ отдать почти весь ресурс GPU одному запросу и снизить риск нехватки памяти.
--gpu-memory-utilization 0.90 разрешает vLLM использовать до 90% видеопамяти. Значение высокое, но оставляет небольшой запас под системные нужды, драйвер и накладные расходы.
--language-model-only загружает только текстовую часть модели. Это полезно, если в репозитории есть дополнительные мультимодальные компоненты, а вам нужен только LLM-инференс.
--reasoning-parser qwen3 включает парсер reasoning-ответов в формате Qwen 3.
--enable-auto-tool-choice разрешает модели самой выбирать, когда нужен вызов инструмента, если клиент передаёт список доступных tools.
--tool-call-parser qwen3_coder подключает парсер tool calls в формате Qwen3 Coder. Он нужен, если вы планируете использовать модель в агентских сценариях с вызовом функций.
--enforce-eager включает eager-режим. Его часто используют ради совместимости и более предсказуемого запуска на новом железе или в сложной конфигурации.
Что можно менять в первую очередь
Если модель не помещается в память, сначала уменьшите --max-model-len, например, до 8192. Это снизит расход VRAM на KV-cache.
Если сервер нужен не только для одного пользователя, можно увеличить --max-num-seqs, но расход памяти тоже вырастет.
Если на машине мало свободной VRAM или параллельно работают другие процессы, уменьшите --gpu-memory-utilization до 0.85 или 0.80.
Итог
Лучше проверять vLLM в два шага. Сначала запустите небольшую модель и убедитесь, что сервер отвечает на запросы. Это быстрый тест окружения. После этого переходите к тяжёлой модели и уже там настраивайте квантование, dtype, KV-cache, длину контекста и лимиты памяти.
Локальная установка через uv даёт больше контроля над окружением. Docker проще переносить и чистить. В обоих случаях результат один: у вас поднимается локальный OpenAI-совместимый API, к которому можно подключать приложения, интерфейсы и агентские системы.

